[CIDR 2022] Are You Sure You Want to Use MMAP in Your Database Management System?
Table of Contents
依稀记得 CMU 有篇 paper 讲了使用 mmap 的各种问题,好奇之前大家使用 mmap 过程中遇到了哪些问题,于是抽空读了这篇论文,加深了我对数据存储、文件 IO 的理解。
Background #
MMAP Overview #
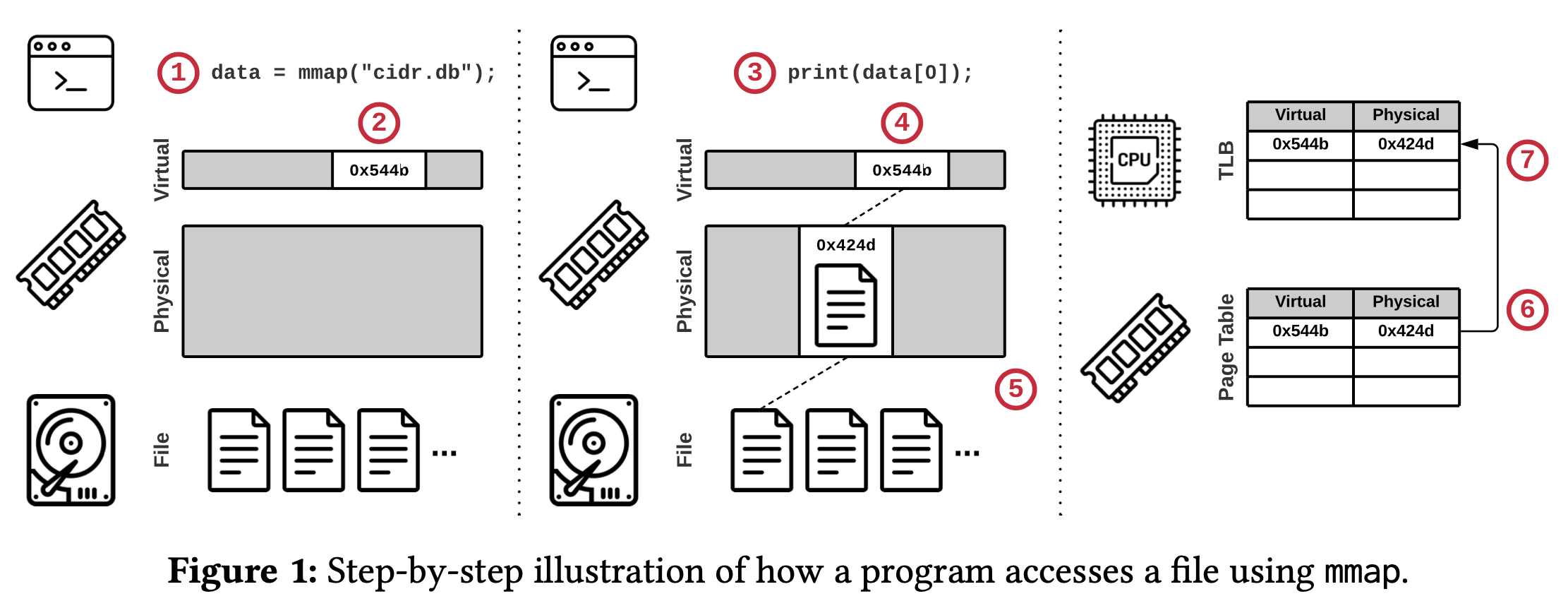
使用 mmap 读写文件内容的步骤:
- 程序调用 mmap,得到指向内存映射文件内容的内存指针
- 操作系统保留程序的虚拟地址空间的一部分,但不加载文件的任何部分
- 程序使用指针访问文件的内容
- 操作系统尝试检索页面
- 由于指定的虚拟地址没有有效的映射,因此操作系统会触发 page fault,将文件的引用部分从磁盘加载到物理内存页中
- 操作系统向 page table 添加一个条目,将虚拟地址映射到新的物理地址
- 当前的 CPU Core 将此条目缓存在其本地的 TLB 中,以加速将来的数据访问
Evict page 会出现一个叫 TLB Shootdown 的严重性能问题。操作系统需要从 page table 和每个 CPU Core 的 TLB 中删除它们的映射关系。清除触发中断的 CPU Core 的本地 TLB 很简单,但清除其他 CPU Core 上的 TLB 会很麻烦,因为当前 CPU 不为远端 TLB 提供一致性,操作系统必须发出昂贵的处理器间中断来刷新远端 CPU Core 的 TLB。从后面的实验结果能看到 TLB shootdown 会带来非常巨大的性能损失。
POSIX API #
mmap:这个调用会使操作系统将文件映射到 DBMS 的虚拟地址空间中,DBMS 可以使用普通的内存操作读写文件内容,通常使用下面两个 flag 来控制 update page 的行为:
- MAP_SHARED:操作系统会先将 page 缓存在内存中,由操作系统控制何时最终写回文件
- MAP_PRIVATE:创建一个仅对调用者可访问的 copy-on-write 映射,page update 不会持久化到文件中。
madvise:使得 DBMS 可以向操作系统提供数据访问模式的 hint,可以是整个文件的粒度,也可以是特定 page 范围。《 madvise(2) — Linux manual page》 列举了完整的 hint 和它们对应的功能。论文描述了三个常用的 hint:MADV_NORMAL、MADV_RANDOM 和 MADV_SEQUENTIAL
- MADV_NORMAL:默认 hint,它会获取访问的 page,以及它前 15 个和后 16 个 page。对于 4KB 的 page,即使调用者只请求单个 page,也会导致操作系统从磁盘中读取总共 128KB 的数据
- MADV_RANDOM:只读必要的页面,对于大于内存的 OLTP workload 来说是更好的选择。MADV_SEQUENTIAL:预读给定范围内的页面,访问后不久可能被释放,对于具有顺序扫描的OLAP workload 来说会更好。
mlock:使得 DBMS 可以将 page 固定在内存中,确保操作系统永远不会将它们 evict 出内存。不过即使 page 被固定在内存中,操作系统也可以随时将脏页(修改后的 page)刷到文件中。DBMS 不能使用 mlock 来保证脏页永远不被持久化,误用可能带来事务正确性问题。
msync:显式地将指定的内存范围 flush 到文件。不显式调用 msync,DBMS 不能保证更新被持久化到文件中。
MMAP Gone Wrong #
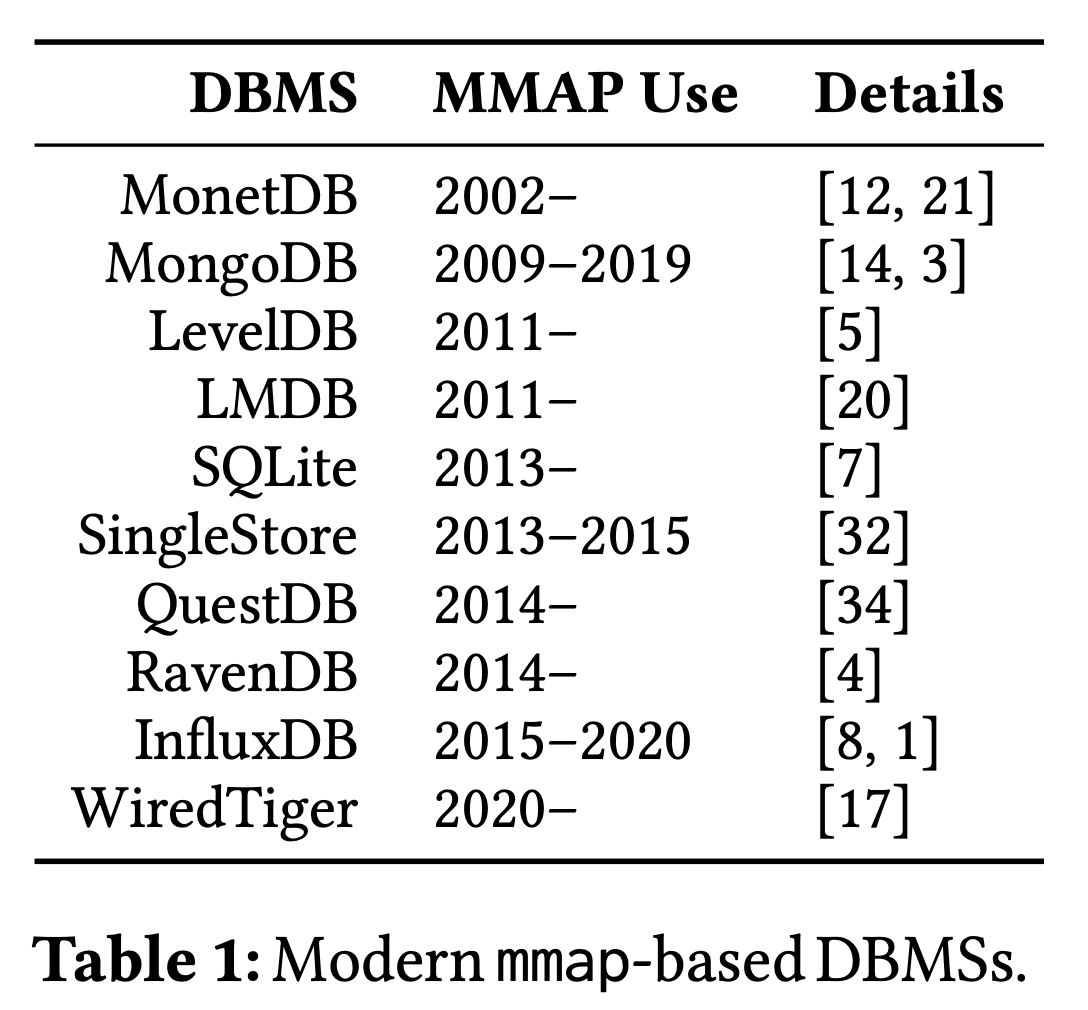
上面是一些使用过(比如 MongoDB),或正在使用 mmap 作为 buffer manager(比如 LevelDB),或提供 mmap 作为 buffer manager 选项(比如 WiredTiger)的 database,作者还举了 MongoDB、InfluxDB、SingleStore 等几个使用 mmap 遇到问题的案例,这些故事比较有意思,有时间可以详细了解下。
Problems With MMAP #
主要是 4 个问题:transactional safety、I/O stalls、error handling,以及 performance issues。前面 3 个都能通过一些额外的稍显复杂的机制来解决或绕过,但性能问题除非修改操作系统内核代码否则无法有效避免。
Transactional Safety #
核心问题是:由于透明分页,操作系统可以在任何时候将脏页刷新到二级存储器中,而不管写入事务是否已提交。DBMS 无法阻止这些刷新,并在其发生时也不会收到任何警告。
论文将解决办法分成了 3 种:OS copy-on-write、user space copy-on-write,以及 shadow paging。
OS Copy-On-Write #
MongoDB 的 MMAPv1 存储引擎采用了这个策略。做法是:使用 mmap 和 MAP_PRIVATE flag 创建两个数据库文件副本,启用操作系统页面的写时复制功能,它们最初都指向相同的物理页面。第一个副本作为主副本,第二个副本则作为私有工作区供事务更新使用。当事务提交时,DBMS 将相应的 WAL 记录刷新到二级存储器,并使用单独的后台线程将提交的更改应用于主副本。
OS copy-on-write 的问题:
- 在允许冲突事务运行之前,DBMS 必须确保提交的事务的最新更新已传播到主副本,这需要额外的 bookkeeping 来跟踪待更新的页面。
- 随着更新的不断发生,私有工作区将持续增长,DBMS 最终可能会在内存中拥有两个完整的数据库副本。也有办法来解决这个问题,只是实现比较复杂,也会引入额外性能开销,这里不再详细描述。
User Space Copy-On-Write #
SQLite、MonetDB 和 RavenDB 采用了这个策略,做法是手动将受影响的页面从 mmap 的内存复制到用户空间中一个单独维护的内存 buffer 内。 在处理更新操作时,DBMS 仅将数据更新应用于单独维护的内存副本并创建相应的 WAL 记录。写完 WAL 即可提交事务,同时也将副本的页面复制到mmap的内存中,交给操作系统去刷盘。
Shadow Paging #
LMDB 基于 System R 的 shadow paging 设计采用了这种策略,做法是维护数据库的单独主副本和影子副本,这两个副本都由 mmap 支持。 处理更新操作时,DBMS 首先将受影响的页面从主副本复制到影子副本,然后应用更新操作。commit 更新操作需要使用 msync 将修改后的影子页面刷新到二级存储器,然后更新指针以将影子副本设置为新的主副本,原始主副本作为新的影子副本。
Shadow paging 需要注意的地方:必须确保事务不会冲突或看到部分更新。例如,LMDB 通过仅允许单个写入者来解决此问题。
I/O Stalls #
mmap 不支持异步读取。因为 DBMS 无法知道页面是否在内存中,如果访问到已经驱逐的页面就会导致意外的 I/O 停顿。这一点和传统的 buffer manager 可以使用 libaio、io_uring 异步读写页面有很大不同。
如何避免呢,其中一个思路是使用 mlock:用 mlock 来固定 DBMS 在不久的将来希望再次访问的页面。但使用 mlock 也是有限制的,因为固定太多页面可能会对并发运行的进程甚至操作系统本身造成一些严重问题,操作系统通常限制单个进程可以锁定的内存量。在这个限制下使用 mlock,DBMS 还需要仔细跟踪和取消固定不再使用的页面,以便操作系统可以驱逐它们。
另一种思路是通过 madvise 告诉操作系统查询的读写模式。例如,需要执行顺序扫描的 DBMS 可以向 madvise 提供 MADV_SEQUENTIAL flag,告诉操作系统在读取页面后驱逐页面并预取下一个将要访问的连续页面。但这种方式也不是很完美:
- madvise flag 只是 hint,操作系统可以自由忽略
- 向操作系统提供不恰当的 hint(例如,随机访问模式下使用 MADV_SEQUENTIAL)可能会对性能产生严重影响
还有一种办法是采用额外的后台线程 prefetch 这些可能访问的 page,尽可能 block 它们而不是主线程。不过这样的代码复杂度很高,违背了一开始因为简单而使用 mmap 的初心。
Error Handling #
使用 mmap 时,DBMS 需要在每次访问页面时验证 checksum,因为操作系统可能会在上一次访问后的某个时间点透明地驱逐页面。而在传统的文件 IO 模式下,只需要在页面从文件中读取时验证 checksum 即可。
使用 mmap 会导致损坏的页面被静默地持久化到文件中,这仍然是因为操作系统可能会透明地驱逐页面导致的。而在传统的文件 IO 模式下,可以在数据写入页面时进行一些约束检查以确保数据没有写坏。
当使用 mmap 时,优雅地处理 I/O 错误变得更加困难,任何与 mmap 支持的内存交互的代码都可能产生 SIGBUS,DBMS 必须通过繁琐的信号处理程序来处理它们。
Performance Issues #
基于 mmap 的文件 I/O 有三个关键性能瓶颈:page table 上的锁竞争、单线程页面驱逐、以及 TLB shootdown。作者认为 mmap 透明分页的最大缺点就是性能问题,如果没有操作系统级别的重新设计,这些问题无法避免。
单线程页面驱逐:作者发现,对于高带宽二级存储设备(比如 PCIe 5.0 NVMe)上的大于内存的 DBMS 工作负载,操作系统的页面驱逐机制无法扩展到多线程上。可能之前的文件 I/O 带宽不高,这个性能问题没有暴露出来。
TLB shootdowns:发生在页面驱逐期间,当前线程所在 CPU Core 需要使远程 Core 的 TLB 映射失效时。刷新本地 TLB 的成本很低,但发出处理器间中断以同步远程 TLB 可以花费数千个 CPU 周期。
Experimental Analysis #
使用 fio 测试 direct IO 的性能,硬件环境:
- AMD EPYC 7713 processor (64 cores, 128 hardware threads)
- 512 GB RAM, of which 100 GB was available to Linux (v5.11) for its page cache
- Samsung PM1733 SSD (rated with 7000 MB/s read and 3800 MB/s write throughput).
Random Reads #
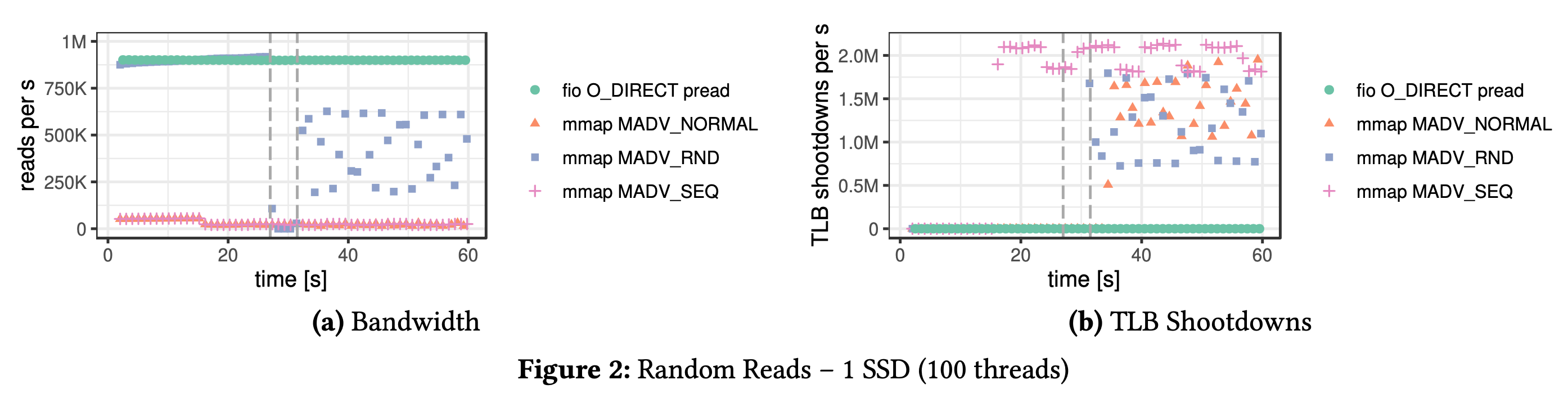
随机读 2TB 的磁盘内容来模拟 larger than memory OLTP 负载,OS page cache 只有 100GB,这个场景理论上来说会有 95% 的 page fault。
从测试结果来看,fio 基准测试表现稳定,每秒读取接近 900K 次,延迟和 NVMe 预期的 100us 差不多,说明 fio 已经充分利用里 NVMe SSD 的读能力。
MADV_RANDOM 的表现非常不稳定:在前 27 秒内与 fio 初始表现相似,然后在大约五秒钟内降至接近 0,最后恢复到 fio 性能的一半。QPS 掉底是因为页面缓存已满,迫使操作系统开始从内存中逐出页面。右图 TLB shutdown 也能大致匹配上。
TLB shootdown 信息可以在 /proc/interrupt 中观测到,TLB shootdown 开销大的原因有:
- 发送一个处理器间中断来刷新每个核的 TLB
- 操作系统只使用一个进程(kswapd)来驱逐页面,在作者的实验中,该进程的 CPU 已经用满
- 操作系统必须同步页表,带来了极大的锁竞争开销
Sequential Scan #
作者首先使用单个 SSD 运行了实验,然后在 10 个 SSD 上使用 RAID 0 重新运行了相同的工作负载(注:软件 RAID 0 是一种 RAID 0 的实现方式,它将两个或多个磁盘驱动器组合在一起,以提高读写速度。RAID 0 不提供数据冗余,因此如果其中一个驱动器出现故障,则所有数据都将丢失):
- 图 3,fio 可以利用一个 SSD 的全部带宽,同时保持稳定的性能
- 图 3,mmap 的性能最初与 fio 类似,但可以再次观察到,在大约 17 秒页面缓存填满后,性能急剧下降。此外,如预期的那样,对于这种工作负载,MADV_NORMAL 和 MADV_SEQUENTIAL 比 MADV_RANDOM 表现更好。
- 图 4,观察到 fio 和 mmap 之间的性能差异约为 20 倍,和图 3 使用单个 SSD 的结果相比也几乎没有性能提升。
Related Work #
作者列举了几个使用 mmap 的研究方向,比如 failure-atomic msync、自己实现系统调用 kmmap 的 Tucana 和 Kreon,以及将 mmap 用在其他方面比如利用 mmap 将冷数据持久化到第二存储等。
最后作者认为像 pointer swizzling 这样设计实现轻量级 buffer manager 才是正确的技术方向,其中两篇 paper 分别来自 TUM 继 Hyper 之后的新系统 LeanStore 和 Umbra,后面有时间详细研究下:
- 《In-Memory Performance for Big Data》,2014,VLDB
- 《LeanStore: In-Memory Data Management beyond Main Memory》,2018,ICDE
- 《Umbra: A Disk-Based System with In-Memory Performance》,2020,CIDR