[DaMoN 2020] Scalable and Robust Latches for Database Systems
Table of Contents

夏特古道,2023
Introduction #
这篇论文不长,主要介绍了 TUM 为 Umbra 实现的 Hybrid Lock,它能同时提供乐观和悲观的上锁方式,通过在不同场景中使用不同的上锁方式来获取更高的性能。本文主要描述 Hybrid Lock 的原理和实现,论文中对其他锁的讨论对我们理解并发和锁也很有启发意义,建议感兴趣的朋友阅读一下原论文:《 Scalable and Robust Latches for Database Systems》
Lock requirements #
作者分析了数据库对锁的能力要求,总结如下:
- 并发读需要尽量快,尽量在多核上 scale,因为包括 OLTP 事务在内的大多数工作负载都是以读为主;
- 对那些采用了代码生成的系统来说,也需要尽量避免外部函数调用;
- 因为锁可能保护非常细粒度的数据结构,因此锁本身的空间开销也应该尽量小;
- 需要尽量高效优雅的处理锁冲突,对于数据库来说,可能线程在锁等待时用户已经取消了查询执行,好的锁实现最好也支持锁等待的线程周期性的检查这类事件,及时响应用户的取消操作。
Optimistic and pessimistic locking #
悲观锁和乐观锁是两种主要的上锁方式:
- 悲观锁:认为这次操作大概率会和其他并发线程产生冲突,在操作数据前先以共享或互斥的方式上锁,线程之间的锁冲突可以在操作数据之前检测到。比如使用常见的 RwLock,在操作数据前先上 Read Lock 或 Write Lock,只有上锁成功后才操作数据。
- 乐观锁:认为这次操作不太会和其他线程产生冲突,使用原子变量的方式为保护的数据维护一个版本号,修改数据时增加版本号,读数据的线程通过对比版本号变化检测冲突,如果冲突就需要重试这次读操作。

上面是实现一个乐观锁的伪代码。读的时候如果发现编码在版本号中的 lock 比特位为 1(表明有人在更新数据),或者读取数据后版本号发生了变化(表明数据已经更新了),这次读操作就需要重试。
乐观锁特别适合用在经常读的热点数据上,比如 B Tree 的 root 节点。使用时需要注意几个问题:
- 乐观锁在碰到写的时候会重试正在进行的读操作,需要确保重试安全。比如读取某个 B Tree 节点,可能别的线程触发了 B Tree Merge 操作导致当前要读的节点被删除了,需要确保重试后数据仍然有效,不会出现访问空指针的情况。
- 上面伪代码传入的是一个 readCallBack,这个 callback 每次重试都会被调用,如果在里面更新一些值,比如 count,那么可能就会因为重试得到错误结果。最安全的做法是仅通过这个 callback 获取数据,等整个读操作返回后才用读到的值去做下一步的计算。
- 当很多线程并发写时,乐观锁很容易被饿死,所以就像伪代码描述的那样,在经历了最大重试次数后需要能够 fallback 到悲观锁。
乐观锁和悲观锁的性能差异主要来自 cache coherence。从上面伪代码可以看出,乐观锁不会修改原子变量的值,这使得各个 CPU core 上的 cache line 一直有效。而悲观锁则因为这些修改操作使得其他 CPU cache 频频失效,导致性能很差。
Hybrid lock #
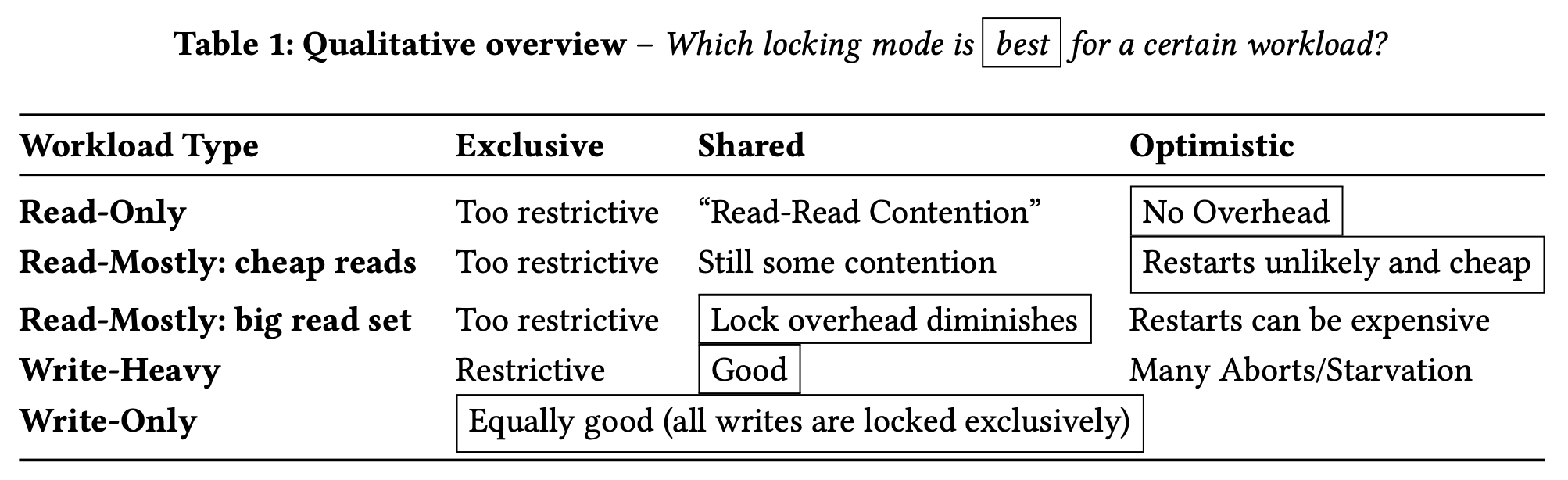
作者将不同场景和对应的最佳的上锁方式整理到了上表中,可以看到除了 read-only 和重试代价低的 read-mostly 场景,其他 3 种场景下使用 shared 或 exclusive 的悲观锁性能会更好。为了获得更好的性能,就需要在不同的上下文使用不同的上锁方式。比如 B Tree,访问 read-contended 上层节点时就可以使用乐观锁,而访问叶子结点去读取数据时就使用悲观锁以避免昂贵的冲突重试。
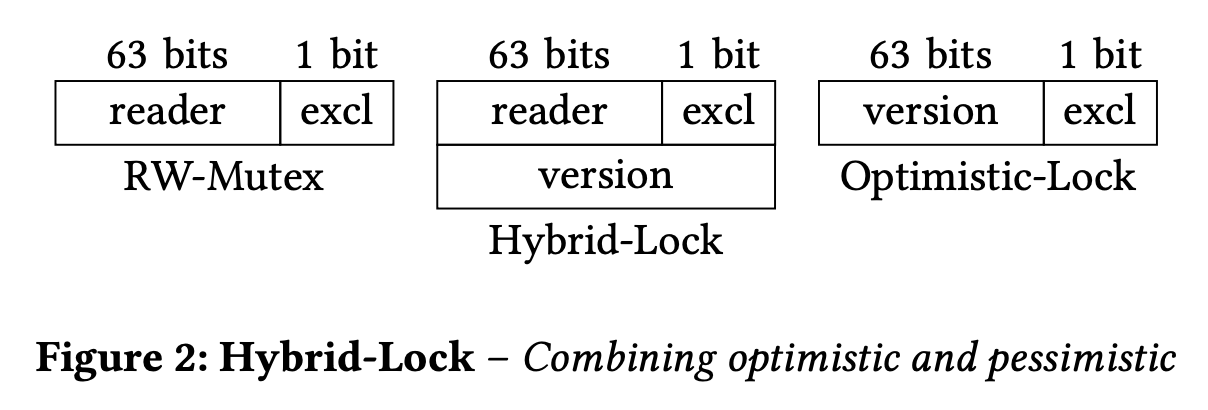
为了达到这个目标,作者设计了一个 Hybrid Lock。如上图所示,这个 Hybrid Lock 内部包含一个 RWMutex 和一个 atomic<uint64_t> 分别用来实现悲观锁和乐观锁,Hybrid Lock 的伪代码如下所示:

需要特别注意 unlockExclusive() 里面两个操作的顺序。因为 tryReadOptimistically() 在执行完 readCallBack 后先检查 RWMutex 再检查 version,unlockExclusive() 里面就需要先 version +1 再释放 RWMutex,确保读操作获取到 RWMutex 后对应的 version 已经更新了,这样它才一定能够检测到这个读写冲突并重试。也可以使用 Intel 的 CMPXCHG16B 指令来同时更新 version 和释放锁。
readOptimisticIfPossible() 和一开始在乐观锁实现中看到的伪代码稍微有点区别。它会在 tryReadOptimistically() 失败后直接从回退到悲观锁,使用 lockShared() 和 unLockShared() 完成这次读操作。
作者在 “2.2 Speculative Locking (HTM)” 中也介绍了 Speculative Locking (HTM) 这类硬件支持的琐实现,没有采用它们是因为它们仅在特殊硬件支持,不够通用。
RWMutex and contention handling #
上面的 Hybrid Lock 还不能完全满足数据库场景的需求,比如在使用普通 RWMutex 时,如果一个线程被锁阻塞,它就会一直阻塞在那,而阻塞过程中用户发起的 cancel query 请求就可能因为长时间的锁等待而迟迟没有被响应。于是 Hybrid Lock 还需要一种能更好的处理锁冲突的 RWMutex 实现。
“3.1 Busy-Waiting/Spinning”、“3.2 Local Spinning using Queuing” 和 “3.3 Ticket Spinlock” 中作者详细介绍和分析了 spinlock 和它的一些变种。整体而言,没有采用它们的原因是希望避免 spinlock 带来的 priority inversion、wastes resources and energy 以及 cache pollution 的问题。
作者参考 webkit 设计和实现了 ParkingLot 的 RWMutex。
ParkingLot #
像 pthread mutex 这类琐实现通常都通过内核系统调用来挂起当前线程直到获得锁为止。但内核的系统调用开销很高,所以也有像 Linux 的 futex 这样的自适应锁实现,仅在锁冲突时才调用内核阻塞当前线程。基于 futex 的思路,WebKit 提出了一个叫 ParkingLot 的自适应锁,也就是这篇论文采用的锁实现。这种实现方式非常通用,可移植性强。
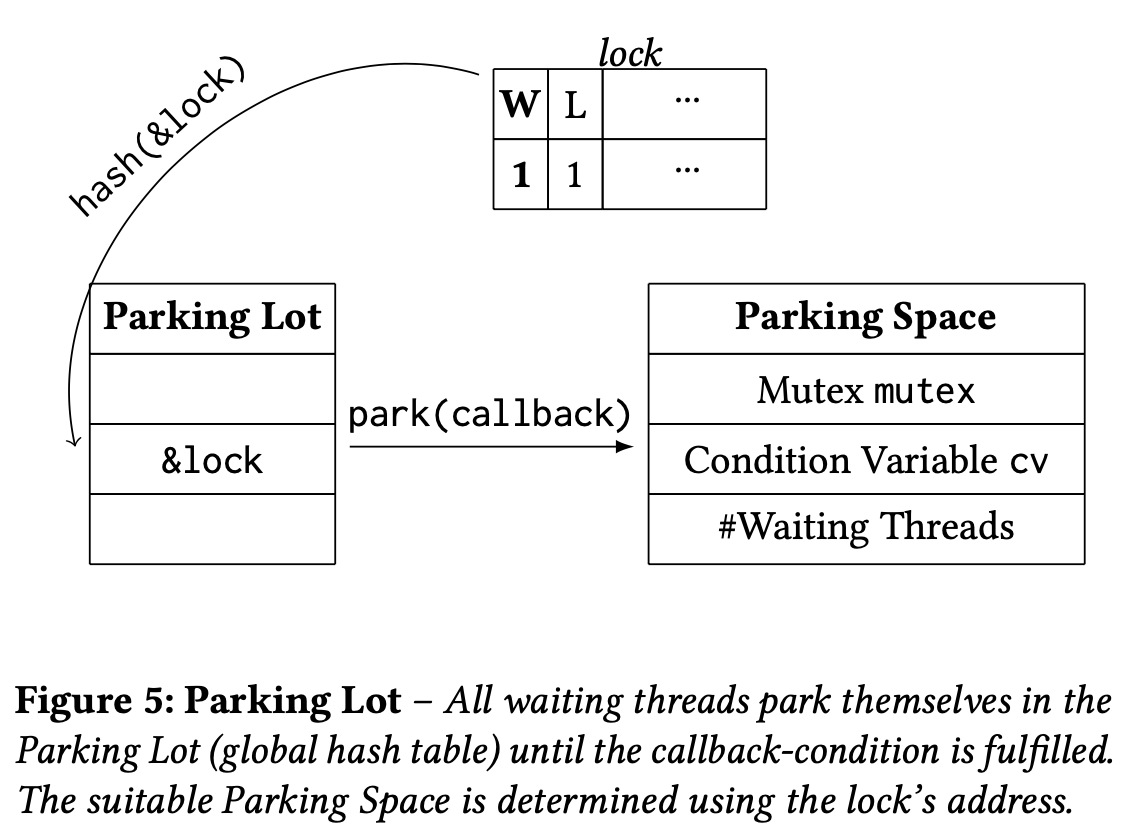
如上图所示,ParkingLot 有 3 个关键要素:
- lock:为方便理解,可以认为它是一个 64 位整数的原子变量,在 ParkingLot 中只使用它的两个比特位,分别是 L 位用来表示是否有线程以 exclusive 的方式持有锁,以及 W 位表示是否有线程在锁等待(发生在某个其他线程以 exclusive 的方式持有锁时)。
- ParkingSpace:每个锁都有一个 ParkingSpace,里面存储了 3 个数据。一个是 WaitingThreads 表示有多少线程正在锁等待,一个是条件变量用来挂起或唤醒当前线程,另一是传统的 mutex 用来保护这个 ParkSpace 本身的并发访问(比如修改 WaitingThreads)
- ParkingLot:lock 地址到对应 ParkingSpace 的全局哈希表。因为冲突的锁数量最多不会超过使用的线程数,ParkingLot 里只有固定的 512 个槽位就足够了,采用拉链法解决哈希冲突。
这种锁实现非常灵活,比如可以在锁等待时可以执行某个 callback,利用这个特性可以在锁等待时检查查询是否被取消,Page 是否已经被缓存替换等。
上图的 ParkingLot 例子中,当前锁的 L 位为 1 表示已经被其他线程持有。当另一个线程想再次获取锁时,它会在 ParkingLot 中等待。此时它会把锁的 W 位设置为 1 表示有人正在等锁,然后使用这个锁的地址在哈希表中找到该锁对应的 ParkingSpace,然后执行 ParkingSpace 中的逻辑。当第 1 个线程释放锁后,它发现 W 位为 1 有其他线程在等锁,它会找到这个锁的 ParkingSpace,利用里面的条件变量将等待的线程唤醒。
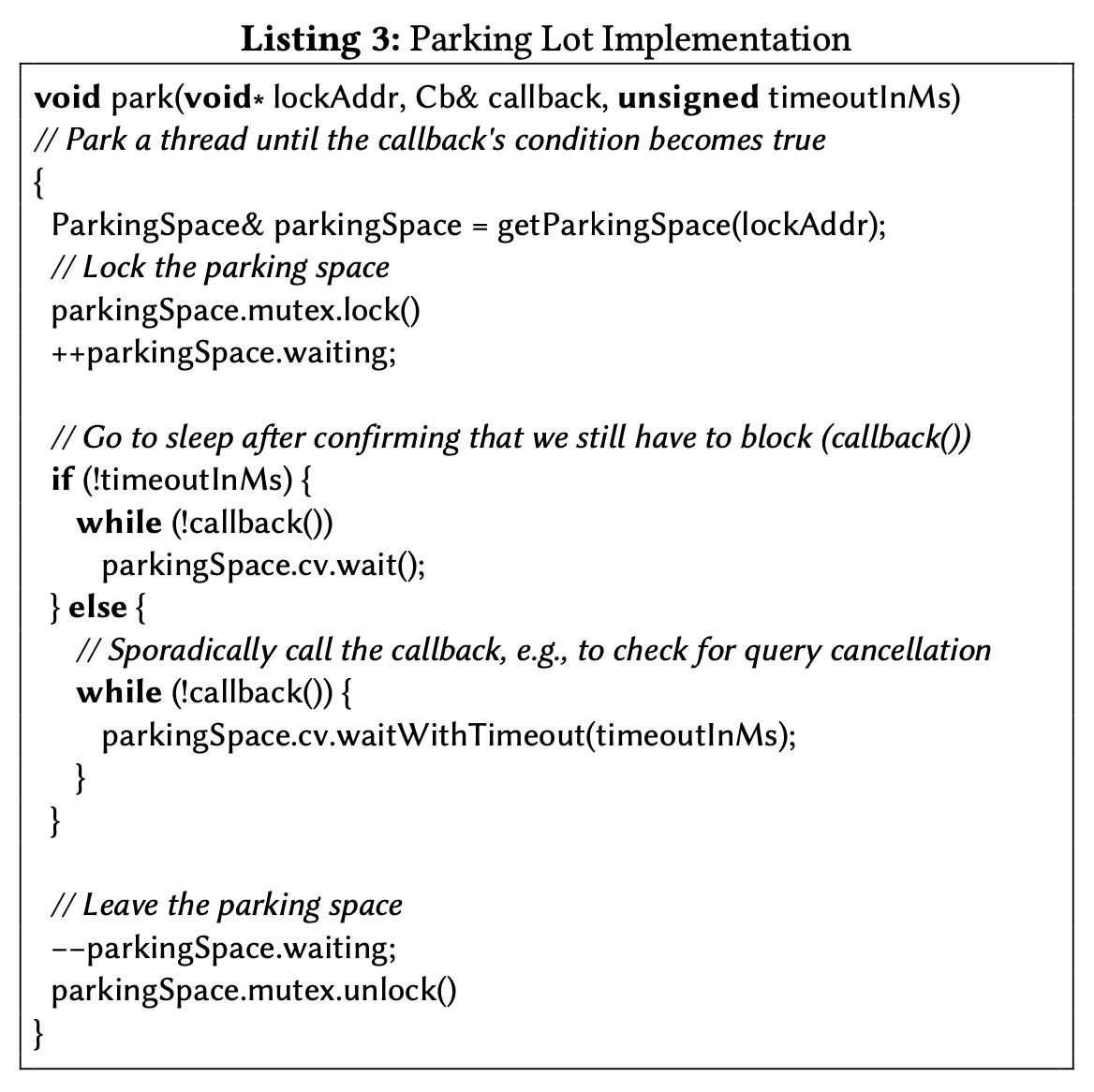
上面是发现 W 位为 1 进行等待时要执行的 park 函数伪代码。在 park 的过程中,先通过锁地址 lockAddr 找到对应的 parkingSpace,把 parkingSpace 的等待线程数 +1,如果没有设置锁等待超时时间,就直接 wait 到被唤醒,然后执行 callback 看是否继续 wait。如果设置了锁等待超时时间,会每隔 timeoutInMs 唤醒一次,执行 callback 看是否需要继续 wait。callback 由调用方提供,比如检查查询是否取消,这样在锁还没获取到但用户已经取消查询的情况下,当前线程就不用继续等待,直接退出执行。
不过仔细 review 这个伪代码,除了检查 callback,应该还需要检查 lock 的 W 列判断锁是否还在,不然可能 callback 返回结果一直为 false,线程一直执行 while 循环。
Takeaways #
以前对锁的使用仅局限于 RWLock,或者干脆 Lock,思维几乎固化。这篇论文让我对锁有了新的认识,HybridLock 和 ParkingLot 的设计确实很巧妙。我想不止数据库,它们用在其他合适的应用场景中应该也能起到不错的效果。