[SIGMOD 1995] A Critique of ANSI SQL Isolation Levels
Table of Contents
前言 #
最近和朋友聊到事务隔离级别(Isolation Level),发现好多东西记得不牢靠。于是捡起 《 A Critique of ANSI SQL Isolation Levels》 重新阅读一把,记录阅读笔记,方便将来再次忘记的时候快速查阅(毕竟中文读的比英文快)。如果文中有描述不恰当的地方,欢迎批评指正。
ANSI SQL-92 根据事务并发执行时可能发生的各种异常现象来定义相应的事务隔离级别,期望通过设置合适的事务隔离级别来避免某些异常现象。在确保业务正确性的情况下,尽量满足性能指标(一般来说事务隔离级别越高,事务的并发性能也越低)。
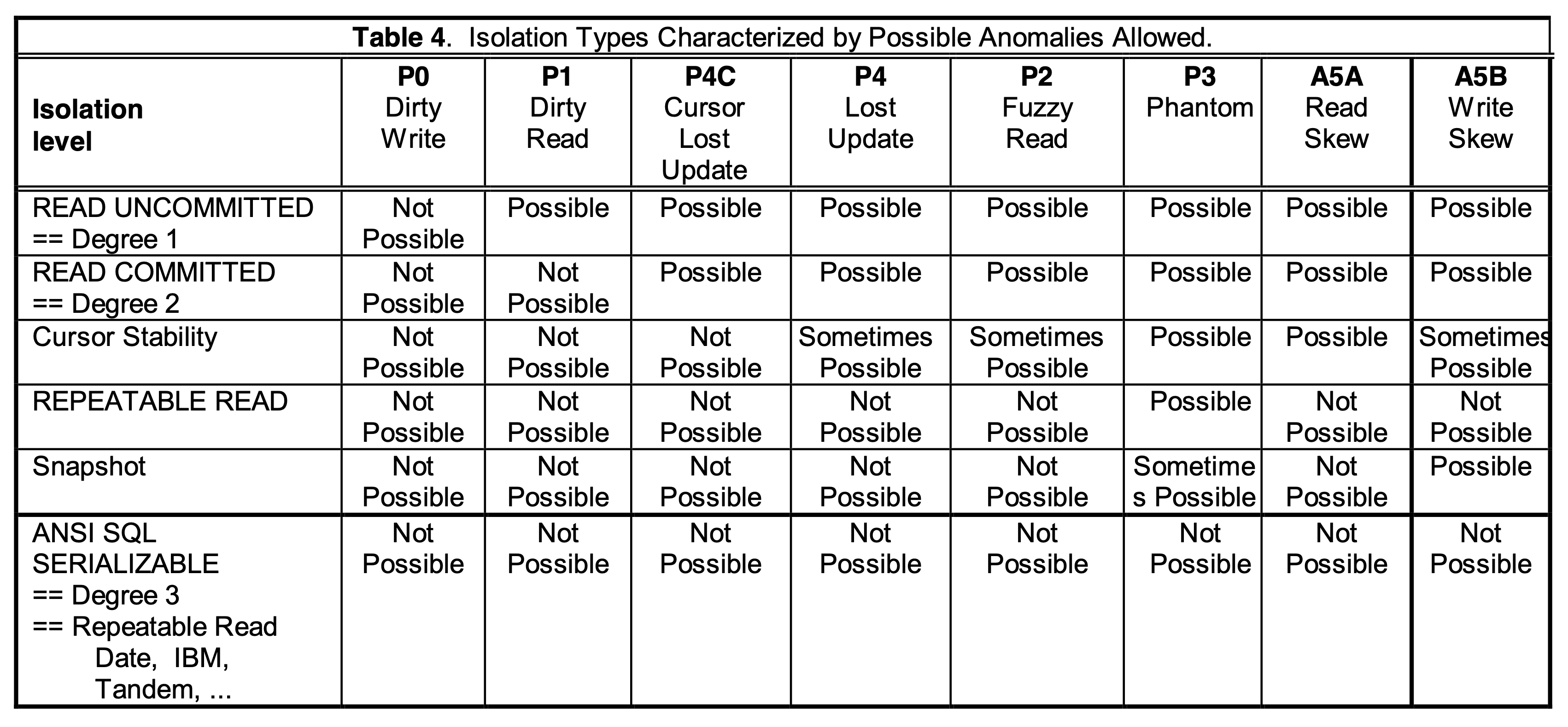
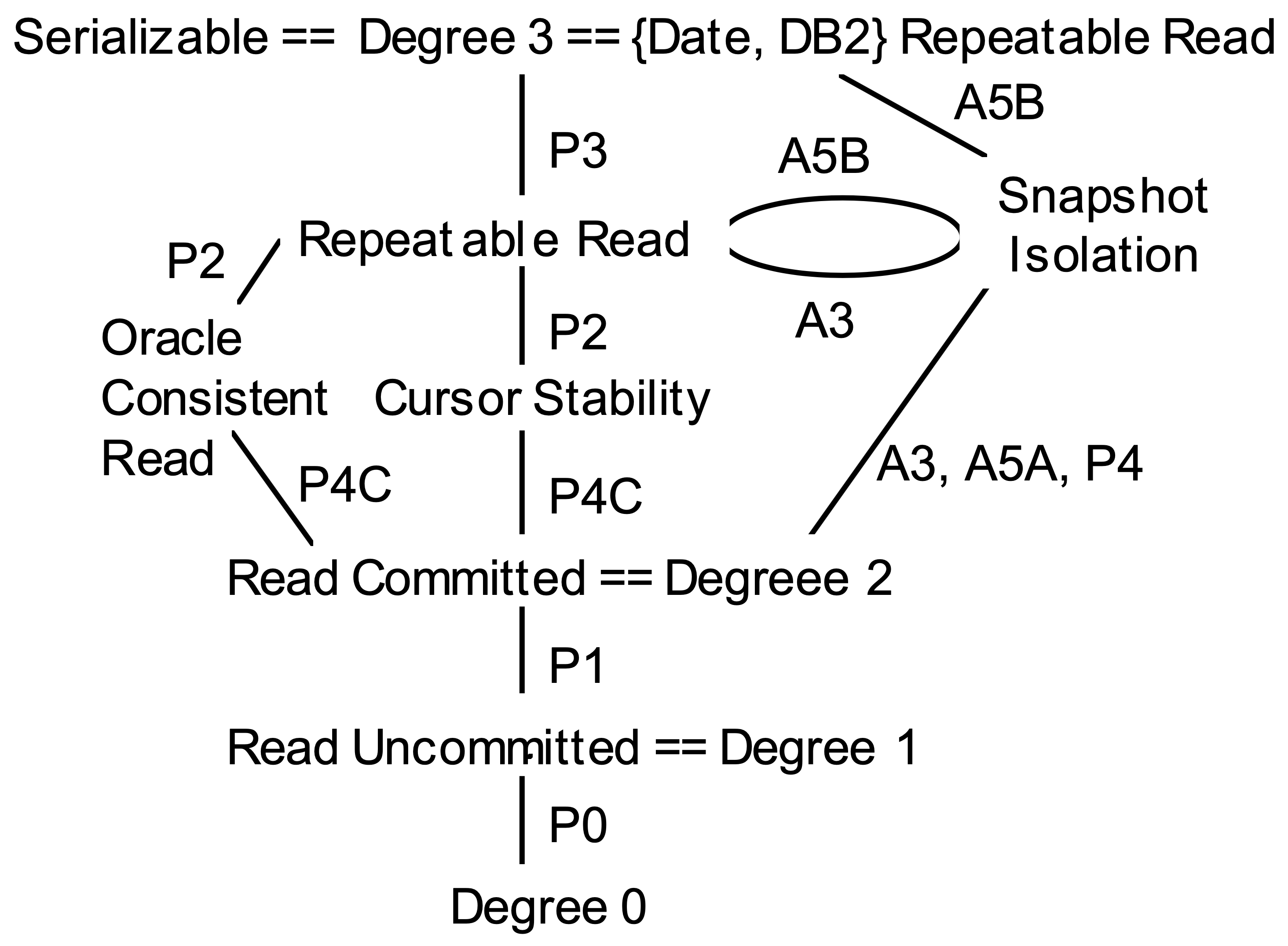
这篇论文在 1995 年发表于 SIGMOD,它指出了 ANSI SQL-92 在事务并发运行时的异常现象描述上存在的一些问题,提出了相应的纠正意见,给出了各事务隔离级别的强弱关系,讨论了快照隔离级别(Snapshot Isolation)的特点以及它和其他事务隔离级别的强弱关系。是理解事务隔离级别非常重要的一篇论文。其中讨论的所有异常现象和事务隔离级别可用下图总结:
锁和事务隔离级别 #
Degree 0:只需要确保每个写操作的原子性就行。在基于锁的事务并发控制中,写操作上 Short Duration Write Lock(写完立马释放),读不上锁。这种事务隔离级别下同时允许 Dirty Read 和 Dirty Write(将在后面介绍)。Degree 0-3 是 Jim Gray 在《 Granularity of Locks in a Shared Data Base》中定义的 4 种隔离级别。并分别和 Read Uncommitted、Read Committed 以及 Serializable 对应,后面不再单独介绍。
- P0 (Dirty Write): w1[x]…w2[x]…(c1 or a1)。事务 T1 先修改了数据 x,接着事务 T2 在事务 T1 提交或者回滚前又修改了 x,如果之后不管事务 T1 提交或者回滚了,数据的约束关系(比如 x=y 的约束)都很难维护起来。P0 是 ANSI SQL-92 中没有描述的一种异常现象,但因为很难保证事务一致性,因此作者认为所有隔离级别都应该避免 P0。
Read Uncommitted:在 Degree 0 的基础上能够避免 P0 的事务隔离级别。在基于锁的事务并发控制中,可以通过读不上锁,写上 Long Duration Write Lock(写的时候加锁,事务提交或者回滚时才释放)来实现 Read Uncommitted 隔离级别。
- A1 (Dirty Read): w1[x]…r2[x]…(a1 and c2 in any order):事务 T1 先修改 x 的值,事务 T2 之后读取 x 的值,读到了事务 T1 未提交的修改值,之后事务 T1 回滚,T2 提交。
- P1 (Dirty Read): w1[x]…r2[x]… (c1 or a1):只要事务 T2 读到了正在执行的事务 T1 写入的数据,后面不管事务 T1、T2 是提交还是取消,就认为这个 Transaction History 属于 Dirty Read,而不是像 A1 那样,还要看事务是否 T1 回滚 T2 提交。如果某个事务隔离级别能够避免 P1,那么它一定也能同时避免 A1。
为了更好的理解 A1 和 P1,让我们来看这么一个 Transaction History:
- H1: r1[x=50] w1[x=10] r2[x=10] r2[y=50] c2 r1[y=50] w1[y=90] c1
为方面大家阅读,我把事务 T1 的所有操作都加粗了。T1 在进行一个转账事务,把 x 的 40 块钱转给 y,事务 T2 是一个只读事务。数据库对外需要维护的约束是 x+y=100。从只读事务 T2 来看,当 T1 写了 x=10 之后,事务 T2 才去读 x 和 y 的值,读出来 x+y=60,不满足 x+y=100 的约束。这个转账的例子中,它没有显式的违背 A1,因为事务 T1 在最后提交了,而不是回滚了。它也没有显式的违背后面会介绍到的 A2:事务 T2 读了 y,接着事务 T1 又写了 y,但事务 T2 在 T1 写 y 之前就提交了,以后不会再去读 y 了。类似的,它也没有显式的违背后面介绍到的 A3。但显然,这是一个 Non-Repeatable Transaction History。
不过别担心,它会被包含作者修订后的 P1 中。P1 并没有限制事务 T1 和 T2 在之后应该是提交还是回滚,以及它们提交或者回滚的时间顺序是什么。P1 所代表的 Non-Serializable Transaction History 集合是 A1 的超集:任何两个事务,只要一个事务读到了另一个正在进行中的事务写的值,就属于 P1 所描述的异常行为。我们通过禁止 P1 所描述的所有异常行为就可以禁止掉上面这种不可串行化的 Transaction History。
通过上面的分析,我们会发现 A1 所描述的 Transaction History 有遗漏,如果只是禁止 A1,仍然会有大量导致异常的 Transaction History 出现,因此 AISN SQL-92 中定义的 Dirty Read 异常行为应该使用 P1 来表示,尽可能多的把一些异常行为包含进去,而不只是狭隘的遵循字面意思。
Read Committed:在 Read Uncommitted 的基础上能够避免 P1(也能避免 A1)。在基于锁的事务并发控制中,可以通过读的时候上 Short Duration Read Lock(读前上,读完立马释放),写的时候上 Long Duration Write Lock(写的时候加锁,事务提交或者回滚时才释放)来实现 Read Committed 隔离级别。
- P4 (Lost Update): r1[x]…w2[x]…w1[x]…c1。事务 T2 对 x 的修改被事务 T1 后续对 x 的修改覆盖了,之后事务 T1 提交,从外界看来,事务 T2 对 x 的修改丢失了。
- P4C (Lost Update): rc1[x]…w2[x]…w1[x]…c1。P4 的 Cursor 版本。如果对 Cursor 陌生,可以看看 MySQL 或者 PostgreSQL 关于 Cursor 的文档。
Cursor Stability:在 Read Committed 的基础上能够避免 P4C(不是 P4)。在基于锁的事务并发控制中,通过对 Cursor 中的读锁进行特殊处理可以实现 Cursor Stability:读锁会一直持有到当前 Cursor 中,直到 Cursor 移动到下一个事务操作时才释放。如果是读满足某个条件的数据,只会上 Short Duration Predicate Lock,读完立马释放。当然,写的时候仍然需要上 Long Duration Write Lock。
- A2 (Non-Repeatable Read): r1[x]…w2[x]…c2…r1[x]…c1。事务 T1 先读 x 的值,接着事务 T2 修改了 x 或者删除了 x 的值并提交,之后事务 T1 再读一遍 x 的值,要么 x 的值和之前不一致,要么读不到 x 了。
- P2 (Non-Repeatable Read): r1[x]…w2[x]…(c1 or a1)。只要事务 T2 修改了在这之前事务 T1 读到过的数据,后面不管事务 T1、T2 是提交还是回滚,就认为这个 Transaction History 属于 Non-Repeatable Read。如果某个事务隔离级别能够避免 P2,那么它一定也能同时避免 A2。另外从上面关于 P4 和 P4C 的定义来看,它们都存在一个事物先读 x 另一个事物再写 x 这种事务历史,所以这种能避免 P2 的事务隔离级别也一定能避免 P4 和 P4C。
类似上面 A1 和 P1 的分析,我们可以通过 H2(r1[x=50] r2[x=50] w2[x=10] r2[y=50] w2[y=90] c2 r1[y=90] c1)来证明,ANSI SQL 所描述的 Non-Repeatable Read 的异常现象应该用 P2 的形式化定义,而不是 A2。
Repeatable Read:在 Cursor Stability 的基础上能够进一步避免 P2。在基于锁的事务并发控制中,可以通过读单个数据的时候上 Long Duration Read Lock,读满足某个条件的数据时上 Short Duration Read Lock,写的时候上 Long Duration Lock 来实现 Repeatable Read 隔离级别。
- A3 (Phantom): r1[P]…w2[y in P]…c2…r1[P]…c1。和 A2类似,不过这次事务 T1 先根据过滤条件 <search condition> 读取数据,事务 T2 接着新增了满足刚才过滤条件 <search condition> 的数据并提交,之后事务 T1 再次根据过滤条件 <search condition> 读一遍数据,结果和之前不一致。
- P3 (Phantom): r1[P]…w2[y in P]…(c1 or a1)。和 A3 类似,事务 T1 先根据过滤条件 <search condition> 读取数据,事务 T2 接着新增了满足刚才过滤条件 <search condition> 的数据并提交,后面不管事务 T1、T2 是提交还是回滚,就认为这个 Transaction History 属于 Phantom。如果某个事务隔离级别能够避免 P3,那么它一定也能同时避免 A3。
同样的,类似 H1 H2,我们可以通过 H3(r1[P] w2[insert y to P] r2[z] w2[z] c2 r1[z] c1)来证明,ANSI SQL 所描述的 Phantom 的异常现象应该用 P3 的形式化定义,而不是 A3。
Serializable:在 Repeatable Read 的基础上能够避免 P3 (Phantom),是最高的事务隔离级别。在基于锁的事务并发控制中,可以通过读时上 Long Duration Read Lock,写时上 Long Duration Write Lock 来实现 Serializable 隔离级别。
论文通过如下方式来比较事务隔离级别的强弱关系:
- L1 « L2:表示隔离级别 L1 比 L2 弱(低),L1 能够避免的异常现象是 L2 的子集。
- L1 == L2:表示隔离级别 L1 和 L2 相等,L1 和 L2 能够避免的异常现象集合相等。
- L1 »« L2:表示隔离级别 L1 和 L2 不可比较,L1 和 L2 分别能避免的异常现象集合没有包含关系,也不相等。
注意上面的方法只适用于比较 Non-Serializable(不可串行化)的事务隔离级别,不同实现方式的 Serializable 之间其实也是有区别的,导致它们能够允许的 Serializable Transaction History 存在些许区别,但不在论文的研究范围内,所以就不展开讲了。
从上面介绍的几种隔离级别我们可以总结出:Degree 0 « Read Uncommitted Read « Read Committed « Cursor Stability « Repeatable Read « Serializable
基于锁的事务并发控制下,根据能够避免的异常现象定义的事务隔离级别介绍完毕,下面让我们来看看 Snapshot Isolation。
MVCC 和 Snapshot Isolation #
Snapshot Isolation 是基于多版本事务并发控制的(MVCC)一种事务隔离级别。在 MVCC 系统中,每个值在写的时候都会被分配一个新的版本号(Version)。每个事务开启的时间点记为该事务的 Start Timestamp,提交时需要获取一个 Commit Timestamp,需要比所有正在进行或已完成事务的 Start 和 Commit Timestamp 都大。
下面我们来看看 Snapshot Isolation 在事务隔离级别中应该处于什么位置。
每个事物只能读到在它的 Start Timestamp 之前提交的其他事务的数据版本。事务 T1 能成功提交的前提是:在它的 Start Timestamp 和 Commit Timestamp 这段时间区间内,不存在任何在这期间提交的事务 T2 和 T1 修改了同样的数据。如果发生了这样的情况,事务 T1 应该回滚。这个特性叫 First-Committer-Wins。显然,这个特性可以可以用来避免 P0 (Dirty Write) 和 P4 (Lost Update)。因为事务读的时候只能读到 Start Timestamp 那一刻数据库的快照和当前事务进行过的修改,所以不难分析 Snapshot Isolation 能够避免 P1 (Dirty Read)。
通过上面的分享,我们发性,Snapshot Isolation 是一个比 Degree 0,Read Uncommitted,Read Committed 和 Cursor Stability 更强的隔离级别。但是因为它不能避免避免下面的 H5,所以它比 Serializable 隔离级别弱:
- H5: r1[x=50] r1[y=50] r2[x=50] r2[y=50] w1[y=-40] w2[x=-40] c1 c2。假设数据库需要维护的约束是 x+y>0,单看 T1 和 T2 都能维护这个约束,而且因为它们并没有冲突的修改同一个值,所以 T1 和 T2 都能执行成功,但最终的结果却变成了 x+y=-80,违背了 x+y>0 的约束,破坏了事务一致性。
那接下里就是和 Repeatable Read 隔离级别相比了,我们会发现,它和 Repeatable Read 是不可比较的(Repeatable Read »« Snapshot Isolation),因为有些 Snapshot Isolation 能够避免的异常现象 Repeatable Read 不能避免,同时有一些 Repeatable Read 能够避免的异常现象 Snapshot Isolation 不能避免。
A5 (Data Item Constraint Violation):假设 C() 是两个数据 x 和 y 之间的一个约束条件,打破 C() 的异常现象可以分为两类:
- A5A (Read Skew): r1[x]…w2[x]…w2[y]…c2…r1[y]…(c1 or a1)。事务 T1 先读了 x 的值,然后事务 T2 接着又更新了 x 和 y 的值并提交。这种情况下,T1 再去读 y 可能就会看到 x 和 y 不满足约束条件的现象。
- A5B (Write Skew): r1[x]…r2[y]…w1[y]…w2[x]…(c1 and c2)。事务 T1 先读了 x 和 y 的值,发现满足约束条件,然后事务 T2 也读了 x 和 y,更新了 x 后再提交,接着事务 T1 如果更新 y 的值再提交。两个事务执行完后就可能发生 x 和 y 之间的约束被打破的情况。上面描述的 H5 就是一个 A5B 的例子,Snapshot Isolation 不能避免 A5B。
Repeatable Read 能够避免的异常现象 Snapshot Isolation 不能避免:因为 A5A 和 A5B 都存在一个事务修改另一个事务读过的数据的情况,所以如果我们能避免 P2(比如事务 T1 读了 x 后,其他事务都不能再写 x),那 A5A 和 A5B 就都能够避免。通过上面的结论,在修正后的 Isolation Level 中,Repeatable Read 是最低的能够避免 P2、A5A、A5B 的事务隔离级别。但 A5B 却不能被 Snapshot Isolation 避免。
Snapshot Isolation 能够避免的异常现象 Repeatable Read 不能避免:Snapshot Isolation 不可能发生 A3 (Phantom) 所描述的异常行为:r1[P]…w2[y in P]…c2…r1[P]…c1,因为事务 T1 是看到的是 Start Timestamp 那一刻数据库快照,看不到未提交的 T2 的更改。但我们上面的分析中,Repeatable Read 不能避免 A3。
另外还要注意到 Snapshot Isolation 不能够完全避免 P3。类似 A5B,事务 T1 根据某个条件读取上来一些数据后,做了修改,事务 T2 也根据同样的条件读取上来同一批数据,但是修改了其他的值,事务 T1 和事务 T2 接下来都能够提交成功。把这样一个多版本系统中的事务历史转换成单版本系统中的事务历史后,会发现这种历史属于 P3 定义的异常行为集合中,因此 Snapshot Isolation 不能完全避免 P3。
总结 #
以这张图结束本文吧,它总结了各种异常现象和能够避免这些异常现象的事务隔离级别: