[SIGMOD 2020] Rethinking Logging, Checkpoints, and Recovery for High-Performance Storage Engines
Table of Contents

夏特古道,2023
简介 #
基于磁盘的 DBMS 通常采用 ARIES 风格的日志恢复机制,它可以处理超过内存的数据和事务,可以在多次崩溃的情况下快速恢复,支持 fuzzy checkpoint 等。然而,ARIES 的中心化日志模块开销很高,不能在现代多核 CPU 上扩展。这篇论文提出适用于多核 CPU 和高性能存储的日志恢复算法。作者扩展了《 Scalable Logging through Emerging Non-Volatile Memory》中的 scalable logging 机制,实现了 continuous checkpoint、高效的页面分配和跨日志文件的 commit 优化。其性能与内存数据库相当。
Scalable Logging #
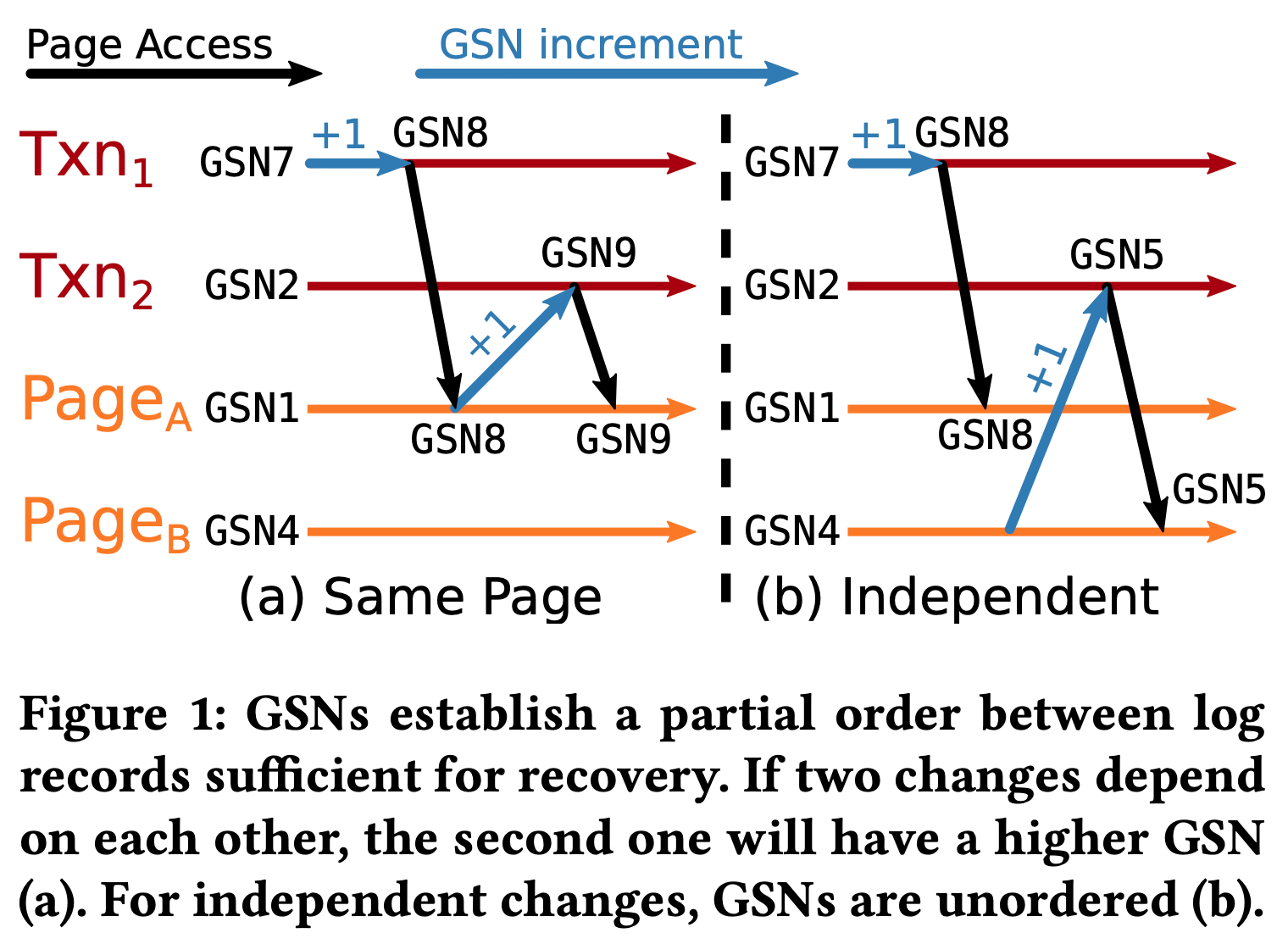
《 Scalable Logging through Emerging Non-Volatile Memory》中介绍的 Scalable Logging 采用多个日志文件来解决并发事务之间的全局锁竞争问题。每个日志文件供一个或多个工作线程独立使用。
GSN(global sequence number):类比分布式时钟,事务和 page 都可以看作是分布式系统中的进程,而 WAL record 则是需要排序的事件。当事务访问 page 时,它的 txnGSN 会被设置为 max(txnGSN, pageGSN),而后续产生的 WAL record 的 GSN 则为 txnGSN+1。这种 GSN 机制可以在不同日志文件的 WAL record 之间建立类似于分布式时钟的偏序关系。当两个事务访问不同的页面时,它们的 GSN 不同步,后 commit 的事务甚至可以有较小的 GSN(如图 1b 所示)。这种机制也保证了每个日志内部的 WAL record 按 GSN 排序。在恢复过程中,page 的日志记录需要从所有的日志中收集,按 GSN 排序后再使用。
passive group commit:在事务提交时,首先会将自己的日志 flush,然后加入到 group commit queue 中等待。等队列中小于该事务 GSN 的所有其他事务 commit 后,当前事务才会 commit,从而维护正确的 WAL record 偏序关系。
这篇论文的方案类似于 scalable logging:每个工作线程都有自己的本地日志文件,WAL record 包含 log type、page ID、transaction ID 以及 before-after image 等信息。在事务提交前,先将该事务的 WAL record 写入 PMEM 缓存中,然后根据作者提出的 Remote Flush Avoidance 机制(简称 RFA)检查是否有其他事务和它修改了共同的 page 产生了依赖关系,并根据需要提交到 group commit 队列中。采用 continuous checkpointing 来平滑 IO,避免突发写入造成事务延迟抖动。
Two-Stage Distributed Logging #
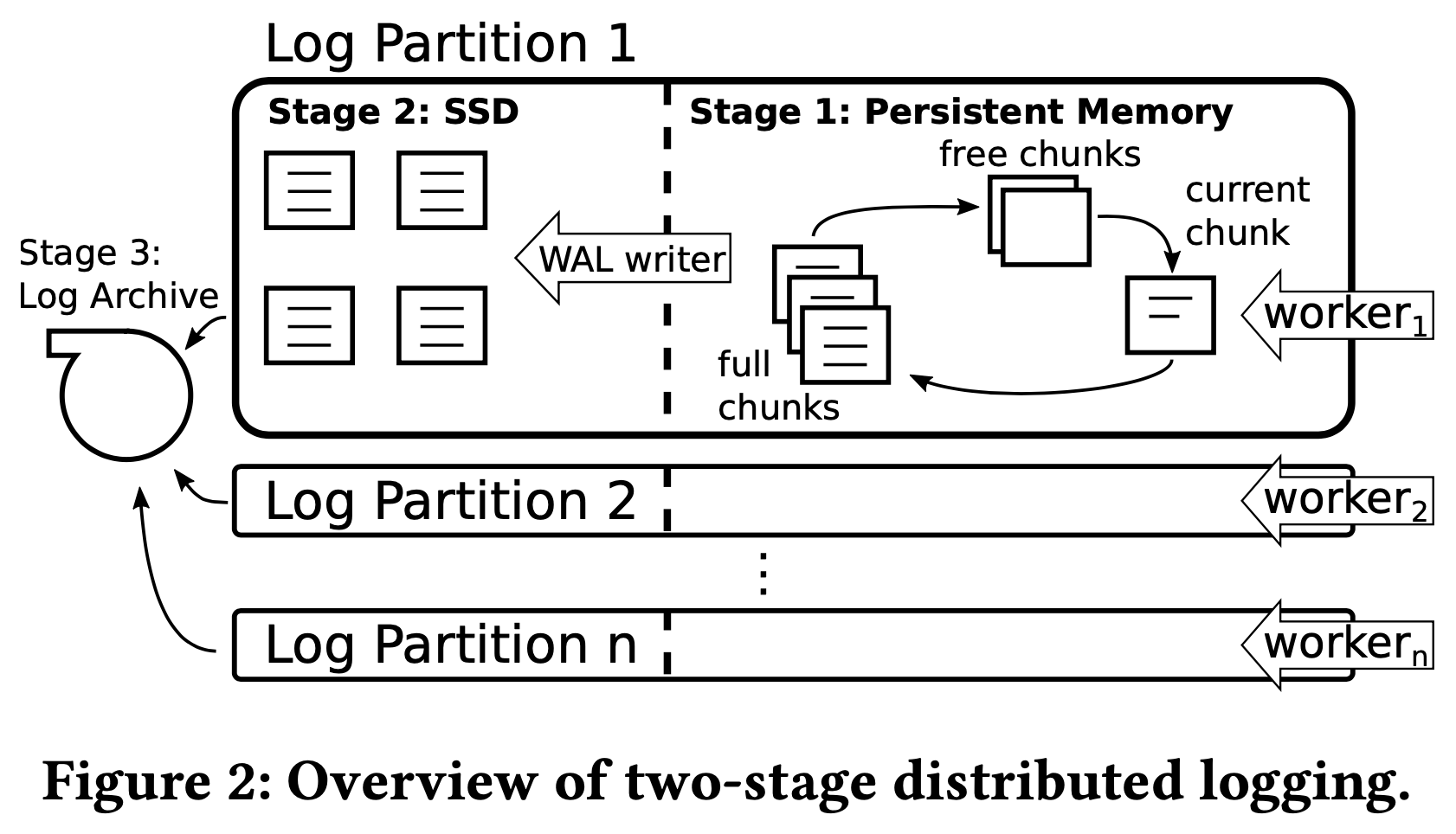
每个工作线程都有自己的本地日志文件,每个事务由一个工作线程完成,WAL record 也写入该线程所属的日志文件中。每个工作线程的日志由 3 个阶段构成:
- PMEM 的 log chunk 组成的循环链表。工作线程不断取出 free chunk 写入当前事务的 WAL。当事务的所有 WAL 在此阶段写入完成时,即可向外部返回提交成功。
- SSD。每个工作线程都有一个 WAL writer 线程,它将 full chunk 写入 SSD,为第 1 阶段提供可用的 free chunk。
Low-Latency Commit Through RFA #
为保证 ACID 中的 C,提交当前事务时需要确保 GSN 小于它的所有事务都已经执行完并且对应的 WAL 已经被 flush。例如:Txn1 在 page a 上删除了一条数据,并在其本地日志 L1 上写下 GSN 为 12 的 WAL;Txn2 在 page a 上插入了一条数据,并在其本地日志 L2 上写下 GSN 为 13 的 WAL。Txn2 的提交需要等待 Txn1 的提交结束,也就是 GSN 13 之前的 GSN 12 也需要被 flush 到磁盘后才能对外返回执行成功:
Timeline
Txn1 (Log=L1)
Txn2 (Log=L2)
1
DELETE(Pa, a1), WAL(L1, GSN=12)
2
INSERT(Pa, a2), WAL(L2, GSN=13)
3
COMMIT
3
COMMIT
这种机制对事务的吞吐量和延迟产生了很大的影响。Scalable logging 采用了 passive group commit 来缓解这个问题。事务的 WAL 在 flush 到本地日志后立即进入全局 commit queue,由 group commit 后台线程周期性地检查所有日志文件中已 flush 的 GSN,以此判断哪些事务可以提交。
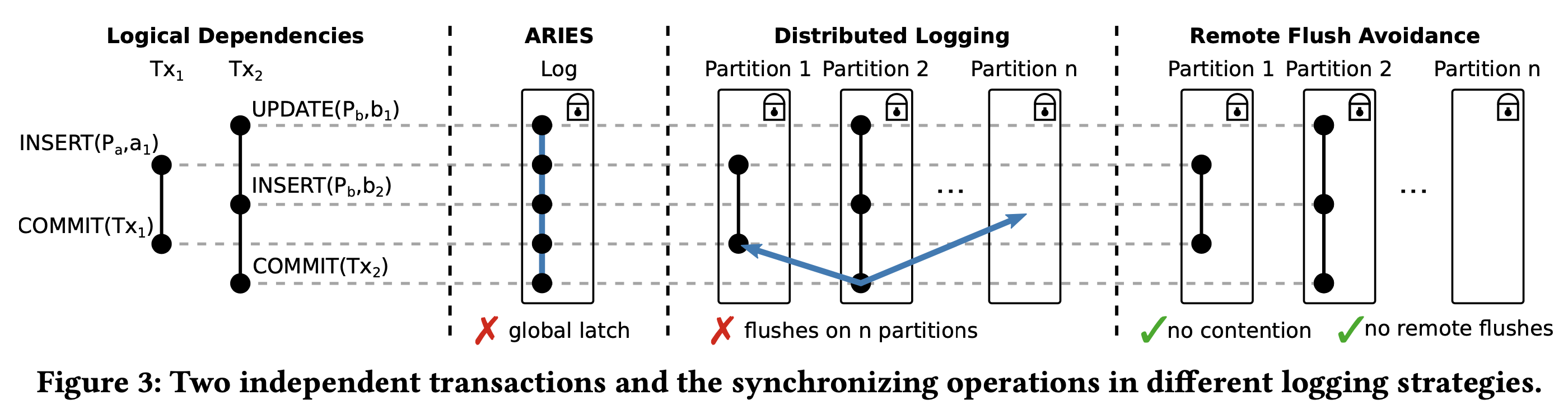
大多数事务是互相独立的,因此即使 GSN 存在大小关系,也可以并行提交。为避免不必要的 group commit,作者提出了一种 RFA(Remote Flush Avoidance)机制来识别互相独立的事务。
RFA 原理很简单:如果该页面上的修改对应的 WAL 已经 flush,或者该页面没有被其他线程并发修改过,则可以跳过 group commit:
- 每个事务开始时,记录所有日志文件的 flush GSN 中的最小值,记为 GSN_flushed。所有进行中的事务写入的 WAL GSN 都一定大于 GSN_flushed。如果 page 的 GSN 不超过 GSN_flushed,则表示该 page 上的修改对应的 WAL 已经 flush 到了各个日志文件中,该事务不依赖于任何未提交的事务。
- 每个 page 记录了上一次的修改者的日志文件,记为 L_last。每次事务修改 page 时,page 的 L_last 都会更新为修改者的日志文件。如果 page 的 GSN 超过了该事务的 GSN_flushed,则说明该事务依赖正在进行的另一个事务(可能是它自己)。需要检查 page 的 L_last 是否与该事务的日志文件相同,以判断是否有其他人修改了该 page。
- 每个事务都会维护 needsRemoteFlush 标志。如果其他事务修改了页面,则该标志设置为 true,该事务需要进入 group commit 队列。如果该事务的所有读写操作结束后,needsRemoteFlush 仍然为 false,则可以跳过 group commit 队列,避免 remote flush。
下图形象的对比了传统 ARIES、普通 group commit,以及经过 RFA 优化的 group commit 在处理互相独立事务时的差异:
Continuous Checkpointing #
continuous checkpoint 希望做到只有新增的 WAL 超过某个阈值时才触发 checkpoint。为了避免扫整个 buffer pool,buffer pool 被分成了 S 个 buffer shard,每次增量 checkpoint 时采用 round-robin 的方式选择一个 buffer shard 进行全量 checkpoint。continuous checkpoint 的伪代码如下:

为了计算 checkpoint 结束后哪些 WAL 日志可以删除,需要如下两个信息:
- buffer pool 的 checkpointed GSN:checkpointer 维护每个 buffer shard 的 checkpointed GSN(也就是上面伪代码中的 maxChkptedInShard[shard]),表示该 buffer shard 上所有 GSN 小于该值的 WAL 都已经被 flush 到了各个日志文件中。整个 buffer pool 的 checkpointed GSN 是所有 buffer shard 的 checkpointed GSN 的最小值。
- 活跃事务的最小 GSN:未提交的活跃事务也会影响 WAL 日志清除,因为在事务 abort 时需要靠这些日志产生对应的 compensation log。因此需要维护所有活跃事务的最小 GSN。
利用 checkpointed GSN 和活跃事务的最小 GSN 即可得出可以被安全清理的 WAL GSN,各个日志文件可以根据它来清理不需要的 WAL 日志。
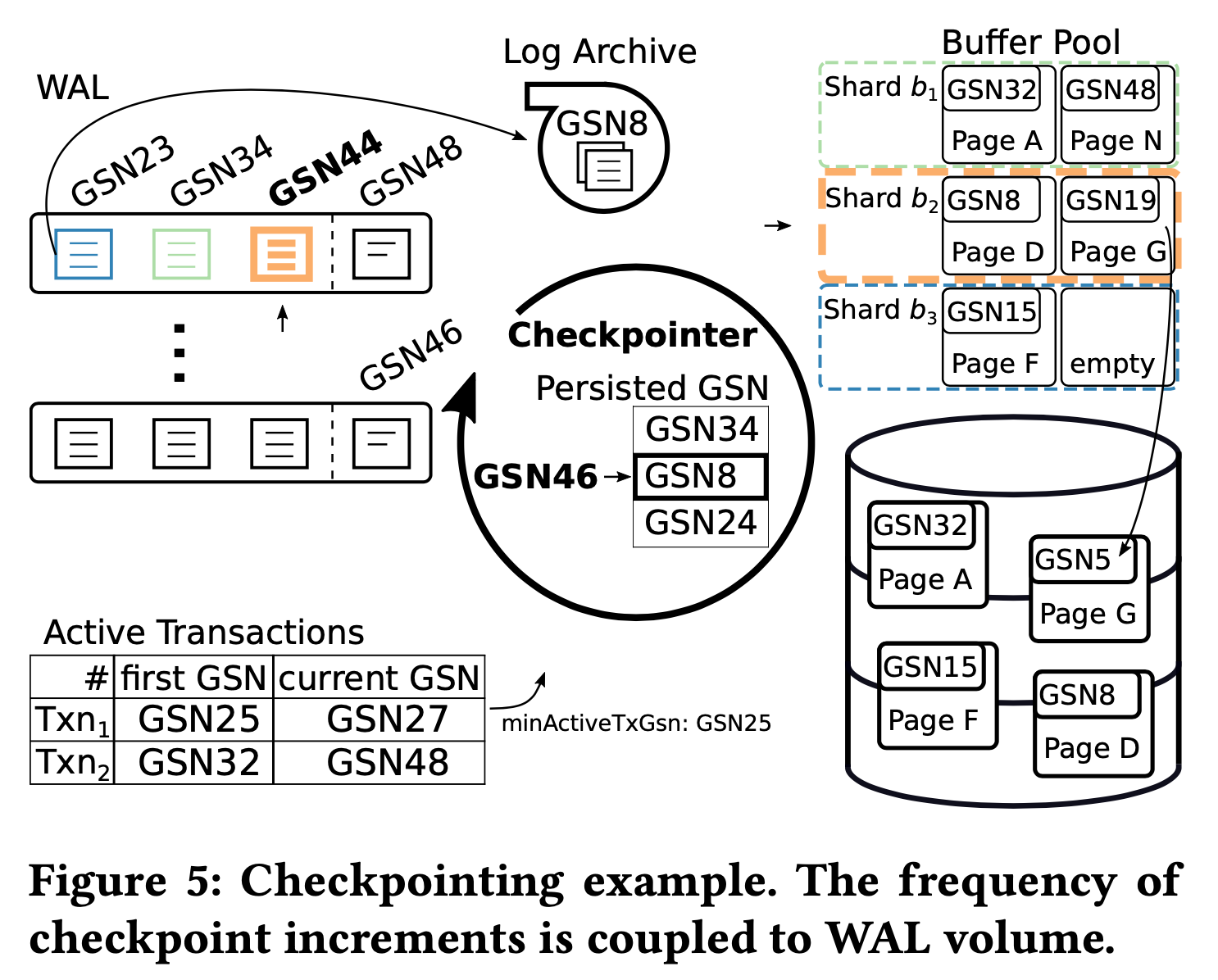
上图展示了一个增量 checkpoint 的例子。buffer pool 被分成了 3 个 shard,每个 shard 有 2 个 page:
- 最近一次增量 checkpoint 发生在 shard b1 上,从中间 checkpointer 维护的 checkpointed GSN 表来看,shard b1 的 checkpointed GSN 是 34。
- 下一次增量 checkpoint 发生在 shard b2,shard b2 此时的 checkpointed GSN 是 8,也是整个 buffer pool 中最小的 checkpointed GSN,而所有活跃事务的最小 GSN 是 27,意味着目前只有 GSN 小于 8 的 WAL 才能被清理掉。
- 对 shard b2 做增量 checkpoint,b2 里只有一个 dirty page G,将 G 写入磁盘后,b2 的 checkpointed GSN 就被更新成了 checkpoint 前所有日志文件最小的 GSN 46。buffer pool 的 checkpointed GSN 也从一开始的 8 变成了 24(shard 3 的 checkpointed GSN)。
Page Provisioning #
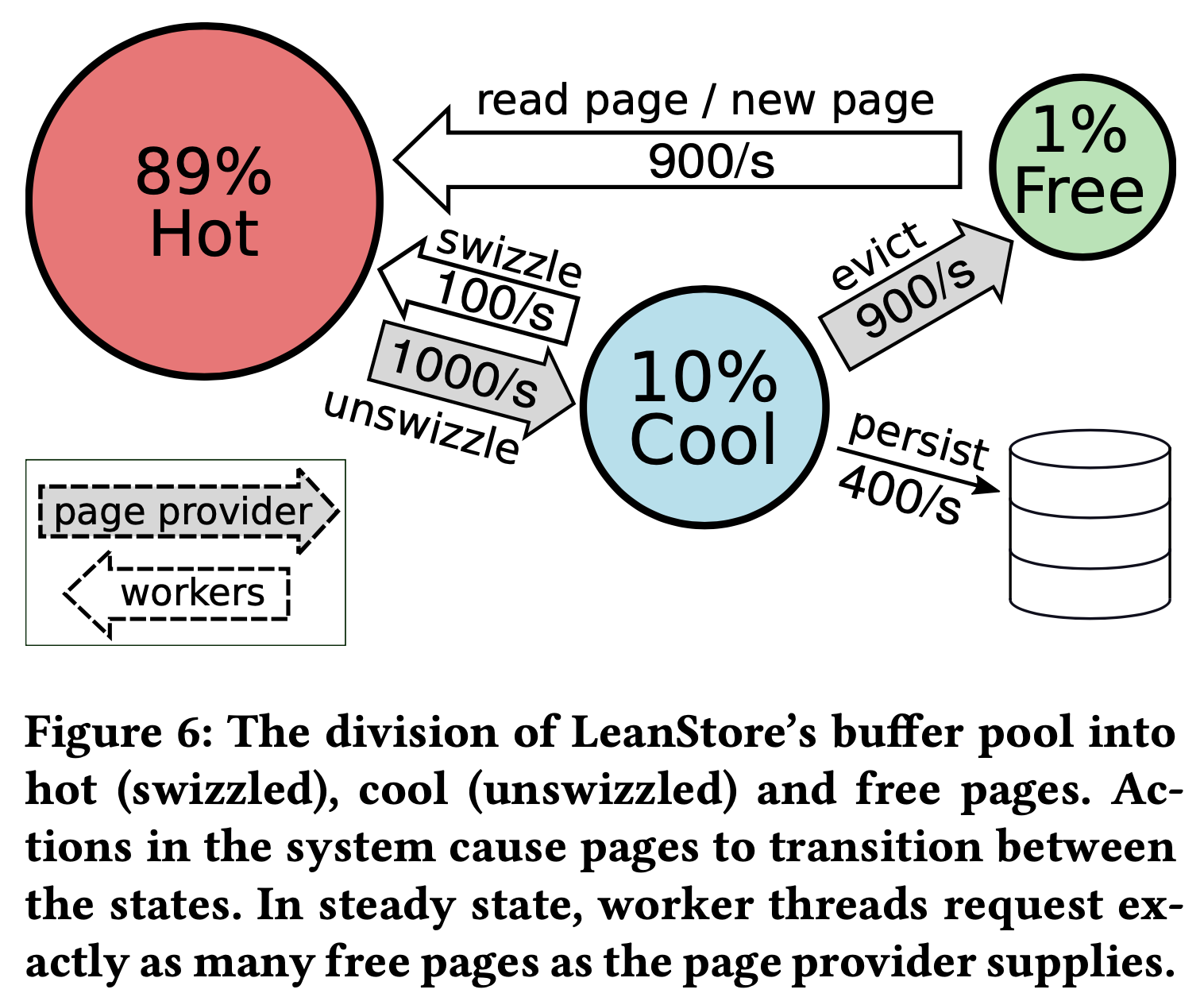
除了 checkpoint,buffer manager 在进行缓存替换时也会将 dirty page 写入磁盘。LeanStore 的 buffer pool 存在 hot、cool 以及 free 三个区域。为了提升工作线程的事务性能,作者使用了一个 page provider 线程来负责 page 相关的 housekeeping 工作,确保工作线程有足够的 free page 可用:
- 挑选 hot page 放入 cool 区域,以及将 cool 区域中的 page 按需移回 hot。
- 驱逐 cool 区域的 cool page(如果是 dirty page 就将其落盘)将 buffer frame 放入 free 区域供工作线程复用。
工作线程发现 buffer pool 偏离它的状态时(比如 hot area 满了)会唤醒 page provider。page provider 多轮运行后,使得 cool 和 free 区域的 page 数量恢复到预设的状态,在每轮运行中 page provider 首先 unswizzle 固定数目的 hot page,比如 256 个,将它们插入 cool 区域的 FIFO queue 的队首,然后从 FIFO queue 的队尾驱逐 cool page。如果是 clean page 就直接出队,清理内存后放回 free list 中。如果是 dirty page 就先保留在 queue 中,先将其标记为 writeBack,拷贝到本地的 writeBack buffer 中。因为仍然在 cool 区域的 FIFO 队列中,在 writeBack 状态的 page 仍然可以被修改,也可以在 swizzled 和 unswizzled 状态之间转换。当 writeBack buffer 填满后,它们才被一次性写入磁盘,更新对应的 GSN 和 dirty 标志。在下一轮运行过程中,page provider 仍然会从 FIFO queue 的队尾取出一个 cool page,这时候如果还是上一次遇到的 dirty page,因为已经写入磁盘且没经过其他修改,所以也不再 dirty,可以直接当做 clean page 处理。
Transaction Abort #
作者和 ARIES 一样采用了 STEAL 的策略,允许未提交的更改写到磁盘上。事务 abort 也需要写 compensation WAL。
Recovery #
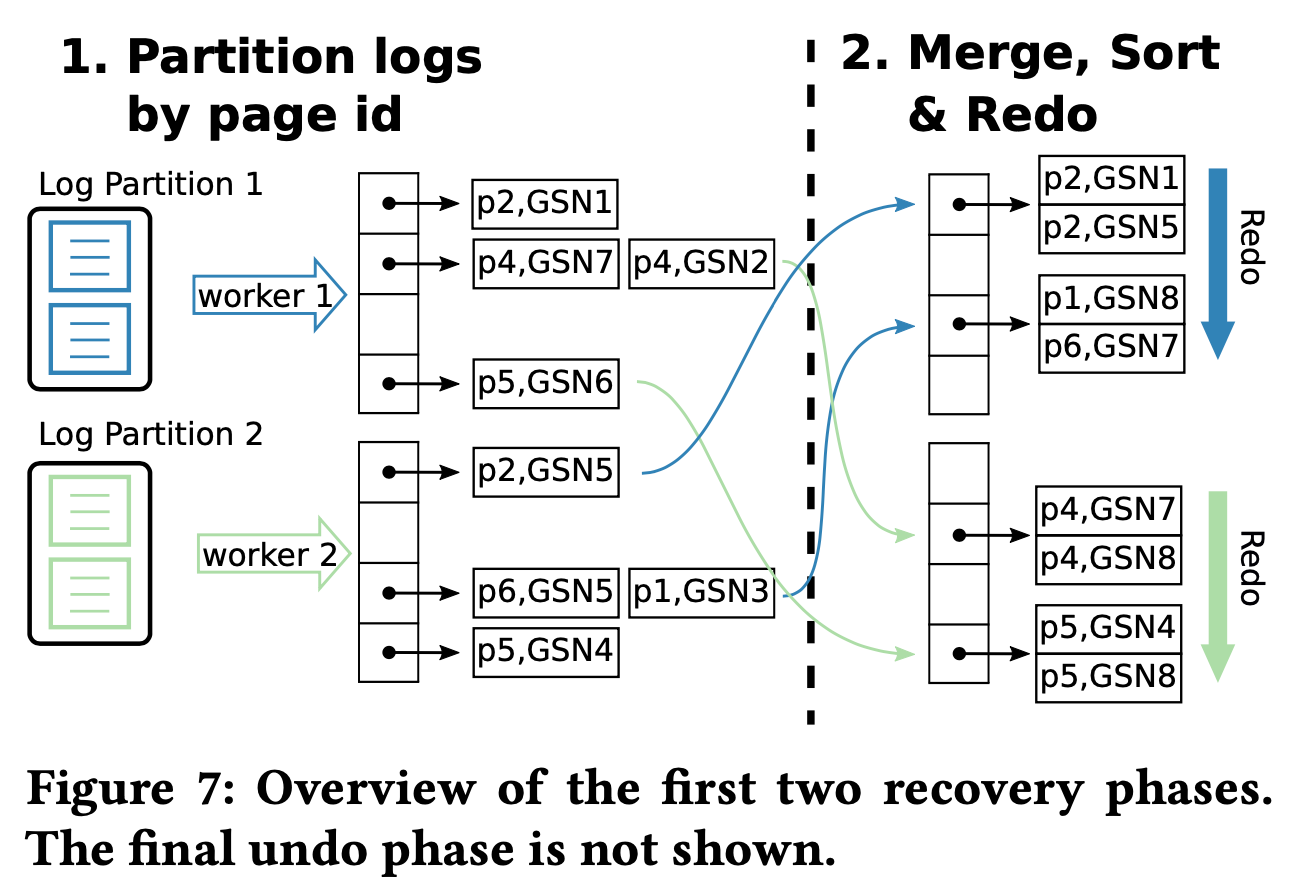
和 ARIES 一样,LeanStore 的 recovery 也分成了 3 个阶段。
- log analysis:每个线程都会扫描包括 PMEM 在内的所有 WAL 日志,分析出执行成功和失败的事务。对执行成功的事务,将对应的 WAL 按照 page ID 进行 partition,对执行失败的事务将他们放到 undo list 中。
- redo:每个线程都分配了一个 page ID 范围,将对应的 WAL 按照 (page ID, GSN) 排序,接着逐个 page 进行 redo。
- undo:遍历需要 undo 的 WAL,进行逻辑上的 undo。
总结 #
以上就是这篇论文提出的日志和恢复机制的核心部分了,论文后面作者也提供了详细的测试结果,感兴趣的朋友可以阅读原文再详细了解下。