[VLDB 2022] Memory-Optimized Multi-Version Concurrency Control for Disk-Based Database Systems
Table of Contents

夏特古道,2023
简介 #
这篇论文主要讲了 Umbra(TUM 实现的 larger-than-RAM 数据库)的高性能 MVCC 实现。作者将事务分为两类,一类是数据修改量不大可以在内存中完成的常规事务,一类是需要修改大量数据的 bulk operation(比如 bulk load)。作者提出了将所有老版本数据存储在内存的 MVCC 实现方案,可以极大加速常规事务的执行。同时也给出了一种应对 bulk operation 的事务执行策略。
基本思路 #
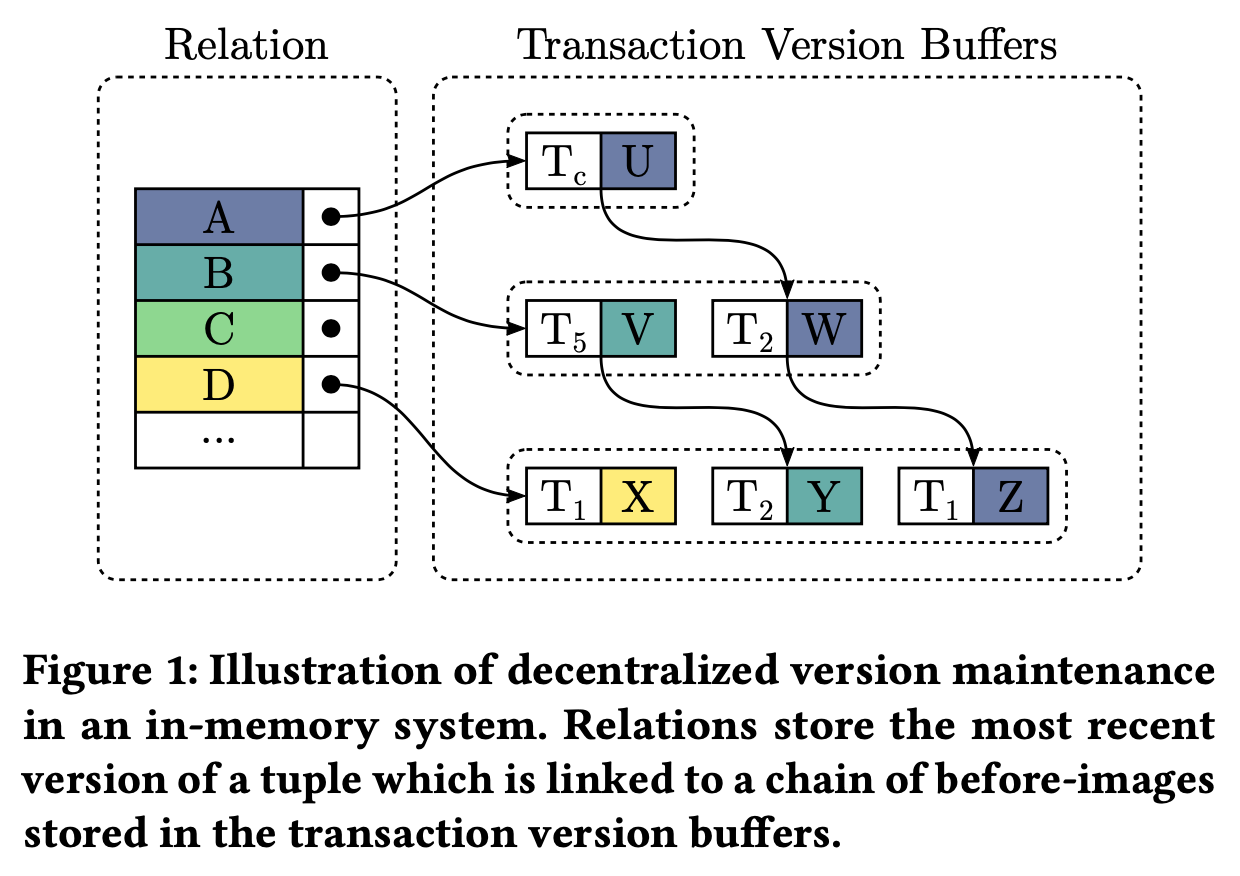
版本链(version chain):每个事务有一个 private version buffer,更新数据时先将旧值从 B tree page 拷贝到 version buffer,标注上当前事务的 transaction ID,然后直接在 page 上原地更新。事务提交时,version chain 上标注的 transaction ID 会被修改为对应的 commit TS。对于表中一行记录来说,所有老版本数据分布在各个事务的 private version buffer 中,以新版本指向老版本的方式组成了 version chain。不再使用的老版本数据会被及时 GC。version chain 上每个数据的版本存储在 chain 的下一个节点上,chain 上最后一个节点没有版本信息。
时间戳:每个事务生命周期内涉及到 3 个时间戳,事务刚开始时会分配 transaction ID 和 start TS,事务在提交时会分配 commit TS。所有事务的 transaction ID 位于 2^63 到 2^64-1 之间,所有事务的 start 和 commit TS 位于 0 到 2^63-1 之间。transaction ID 使用一个 TS 生成器分配,start 和 commit TS 使用另一个 TS 生成器分配,TS 需要保证单调递增。
可见性:数据的每个版本都有一个时间戳,要么是 commit TS 要么是 transaction ID。事务在读数据的时候从 page 上的数据开始遍历它的 version chain,只有满足这些条件之一的才对当前事务可见:
- 当前数据没有版本信息,比如没有 version chain 的数据,或者 version chain 最末尾的数据
- 当前数据的版本(存储在 version chain 的下一个节点上)等于当前事务的 transaction ID,表明这个数据是当前事务修改的
- 当前数据的版本小于等于当前事务的 start TS,表明它是一个在 start TS 之前已提交事务的执行结果
比如上图,假设有个 transaction ID 为 Tc 的活跃事务,它的 start TS 是 T2,它读左边这个表时能看到的数据是:
- 第 1 行是 A:A 的版本是 Tc,和它的 T 的 transaction ID 相等,可见
- 第 2 行是 V:B 的版本是 T5,大于 T2,不可见;而 V 的版本是 T2,小于等于 T2,可见
- 第 3 行是 C:这个 tuple 没有 version chain,可见
- 第 4 行是 D:D 的版本是 T1,小于等于 T2,可见
面向常规事务的内存 MVCC #
版本管理 #
为了解决内存不足,同时也不影响在线事务的性能,大家通常都会采用 STEAL 的方式将包含未提交数据的脏页和 version chain 一起写入磁盘。这种做法资源利用率不高,事务的执行性能也不好。Umbra 将数据和他们的 version chain 分开,只将原地更新的最新数据(可能没提交)页写入磁盘,version chain 保留在内存中,这样能够减少写放大的问题,同时因为有 WAL,事务的 durability 也能得到保障。
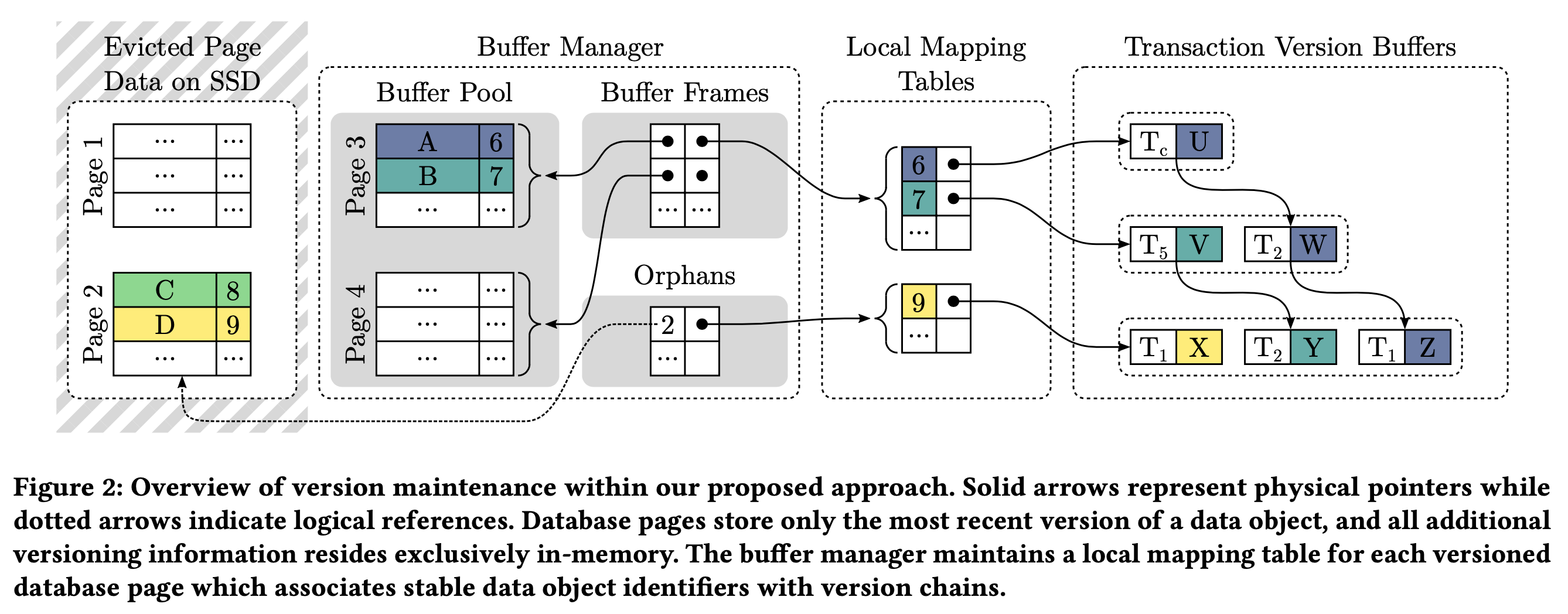
如上图所示,Umbra 采用了去中心化的方案,为每个 page 单独维护一个 local mapping table,里面存了数据对象(比如 tuple ID)到内存 version chain 的映射关系:
- local mapping table 按 page 拆分后和 page 使用同一个 latch 保护,在读写 local mapping table 时避免了整库大锁
- version chain 上的节点处于不同的事务的 virtual version buffer 中,事务在更新节点上的数据版本为 commit TS 时也不需要获取 page 上的 latch
那如何找到某 page 的 local mapping table 呢。如果该 page 已经加载到内存中,会直接在存储 page 内容的 buffer frame 上增加一个指向该 local mapping table 内存指针,这样访问 page 内容时就可以直接通过这个指针找到对应的 local mapping table。
当内存中的 page 被替换到磁盘后,Umbra 将其 page ID 和 local mapping table 插入到内存中维护的 orphans 哈希表中,这个哈希表存储了所有写入磁盘后的 page 的 local mapping table。等之后磁盘上的 page 再次加载进来时就可以通过访问这个哈希表找到对应的 local mapping table,将它和 page 内容加载到内存的 buffer frame 中去,同时也从这个 orphans 哈希表中移除。
垃圾回收 #
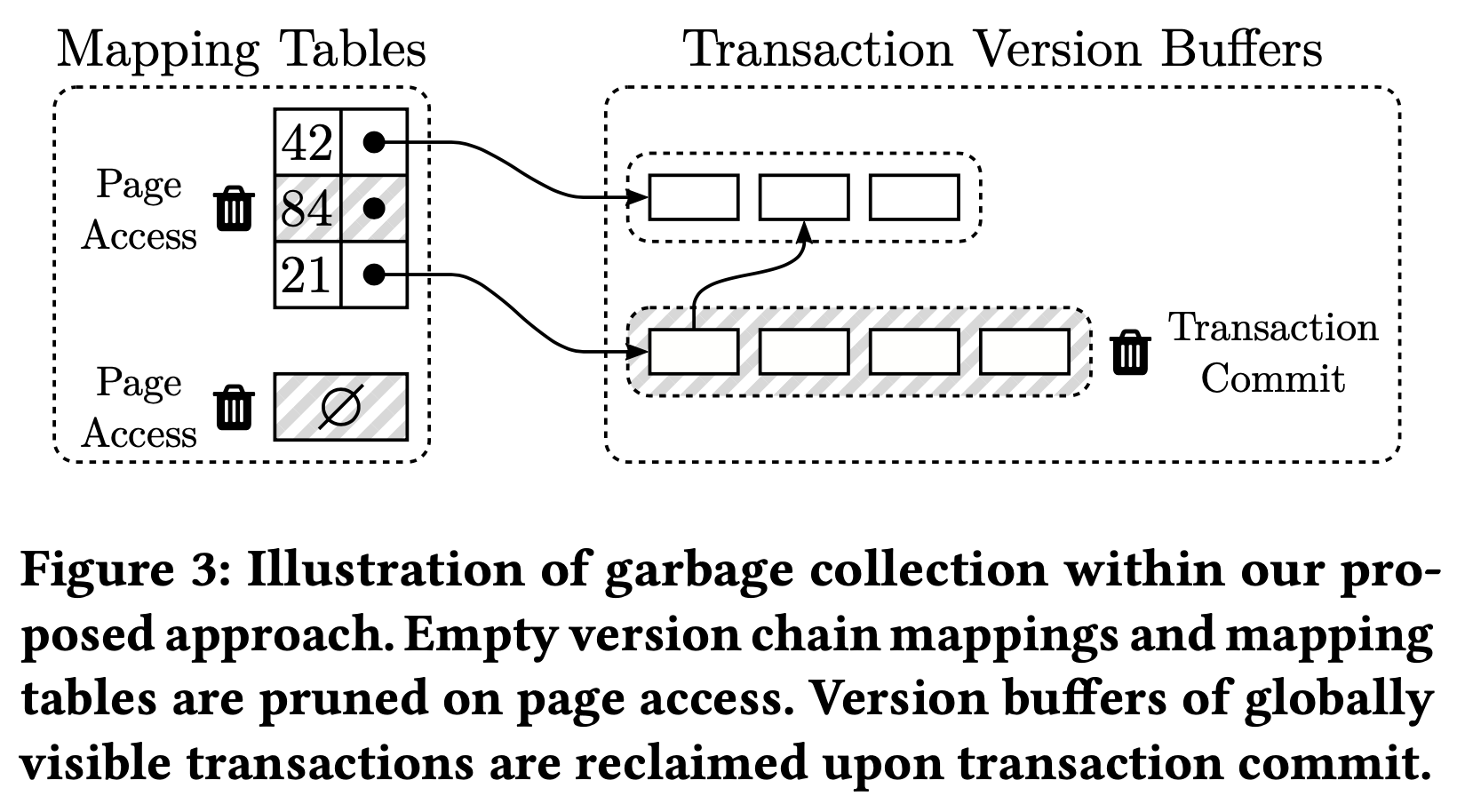
Umbra 采用《 Scalable Garbage Collection for In-Memory MVCC Systems》(同样来自 TUM,2019 年发表在 VLDB)中提出的 Steam GC,将垃圾回收工作分散在不同的组件和工作线程中,尽可能以去中心化方式进行 GC。在 Umbra 中,只有 version buffer 和 local mapping table 这两个地方会产生需要清理的“垃圾”,GC 主要围绕它们进行。
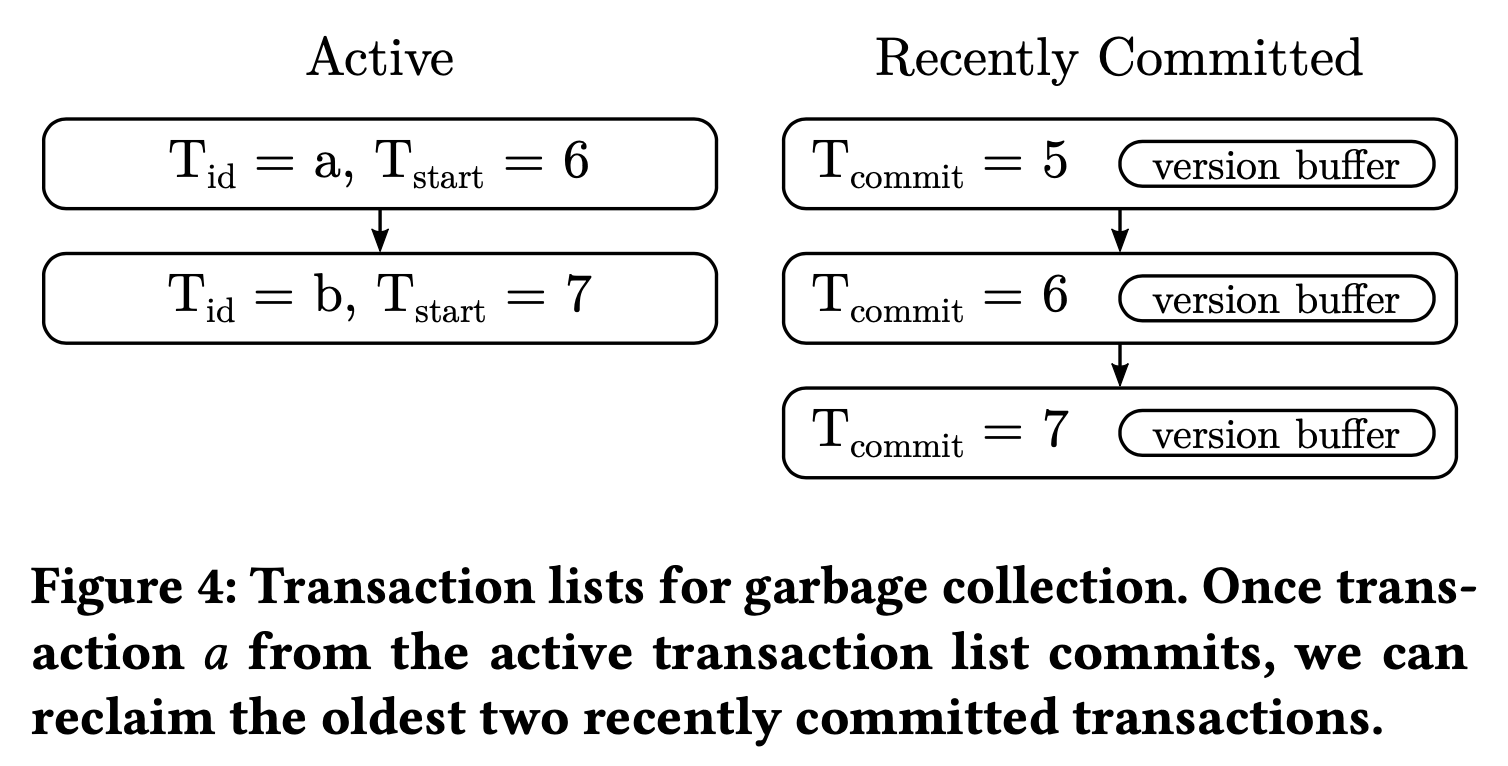
如何清理各个 version buffer 呢?Umbra 维护了两个 ordered linked list。一个是 active list,用来存放所有活跃事务,一个是 recently committed list,用来存放所有已提交的、有数据修改的事务,只读事务不产生新版本数据,可以忽略。在事务提交时获取 active list 中最小的 start TS,这个 TS 表明现在和将来不会再有任何事物去读比它更旧的数据了,之前的版本可以放心清理掉。接着在 recently committed list 中寻找 commit TS 小于它的已提交事务,清除他们的 version buffer。清理 version buffer 可能使一些 version chain 为空,在后续 local mapping table 的 GC 中被清理。
对于经常访问的热点 page,它们的数据版本能够很快的 GC 掉。但是其他冷 page 可能就得不到处理,它们对应的 local mapping table 遗留在之前提到的 orphans 哈希表中。为了清理这些 local mapping table,buffer manager 会在 page IO 时 GC 这些 local mapping table。
那如何清理各个 local mapping table 呢?Umbra 在常规的 page 维护工作(比如 page compaction)中新增了 local mapping table 的清理工作。在这些维护工作结束前遍历 local mapping table,清理空的 version chain,最后再清理空的 local mapping table。为了减少遍历 local mapping table 的次数和开销,Umbra 为 local mapping table 维护了一个 number of empty version chains 的统计信息,只有空 version chain 的比例超过一定阈值(比如 5%)时才去遍历和清理 local mapping table。
恢复 #
在发生系统故障时,内存中的 MVCC 版本信息(主要是 version buffer 和 local mapping table)可以安全的丢失,因为这些信息已经包含在 WAL 中了。在故障恢复后,所有未提交的事务都被 undo,整个数据库恢复到了一致的状态,没有任何活跃事务和 version buffer,数据只会有一个已提交的最新版本,没有 version chain,local mapping table 也为空。之前用来分配 transaction ID 和 start、commit TS 的时间戳计数器也可以重置,重新开始计数。
Umbra 的一条 WAL record 包含了多个数据对象的 before-after image,在恢复的 undo 阶段或者正常 abort 事务时需要格外注意。undo 某个数据对象时,需要不断扫描该事务的各个 WAL record,找到这个数据的 before-after image,把 page 数据修改为 before image,把数据版本从 version chain 中清除,同时记录对应的 compensation log record。
实现细节 #
Umbra 在实现上尽可能避免中心化的数据结构和操作,提升系统在多核上的 scale 能力。
每个工作线程会各自维护自己的 active 和 recently committed list。小事务由单个工作线程执行,按照上面的垃圾回收策略做 thread-local 的 MVCC GC。
大事务可以使用多个工作线程执行,维护在全局的 active 和 recently committed list 中,因为同时执行的大事务不多,这个全局 latch 的锁竞争不会成为主要性能瓶颈。大事务执行时内部也会维护自己的 version buffer,避免 version 分配时和其他单线程执行的小事务产生争用。
利用原子变量实现了一个轻量化的 latch 来保护 version chain,使得 version chain 的 GC 不会影响 version chain 的并发读。这个轻量化 latch 可以参考《 Scalable and Robust Latches for Database Systems》(同样来自 TUM,2020 年发表在 VLDB)提出的 HybridLatch,也是在 Umbra 上的工作成果。
面向 Bulk Operation 的磁盘 MVCC #
并不是所有事务修改的数据量都很小能够在内存中完全放下,因此需要一种机制来处理内存放不下的大事务。而从场景来来看,作者认为这样的操作要么是偶发的系统管理任务,要么是用户不小心写的 buggy query。
另外作者认为仅需要支持串行 bulk operation 即可,原因是每个 bulk operation 理论上都会极大消耗系统的写带宽,而且因为 bulk operation 涉及的数据量很大,并发的 bulk operation 之间很容易冲突,所以允许多个 bulk operation 并发执行没啥好处。而且为了避免 bulk operation 和用户事务冲突而 abort,在 bulk operation 开始后 Umbra 只允许 read-only 的事务并发执行。
作者在后面提出了一些思路来解决这些限制,使 bulk operation 可以和其他 bulk operation 以及写事务并发,我们先来看整个 bulk operation 的 MVCC 是如何做的。
Versioning Protocol #
虚拟版本(virtual version):bulk operation 产生的数据版本称为虚拟版本,bulk operation 仅会生成 created 和 deleted 两种虚拟版本,内存中常规事务产生的数据版本称为物理版本(physical version)
epoch:Umbra 维护一个全局单调递增的 epoch 生成器,epoch 的范围在 0 到 2^64-1 之间。每个常规事务和 bulk operation 开始时都会获取 start epoch,bulk operation 所产生的数据虚拟版本就是它的 start epoch 值。常规事务获取的是最近已分配的 epoch,而 bulk operation 获取是下一个未分配的 epoch,当 bulk operation 完成时才更新全局 epoch 到它刚才获取的这个 start epoch。这个全局 bulk operation epoch 每次系统重启前都会持久化到磁盘,epoch 计数器的推进也需要记 WAL 确保 durability。
可见性:基于上面描述的 epoch 机制,可见性就比较简单了。对每个常规事务来说,当且仅当它的 start epoch 大于等于当前数据的虚拟版本时该虚拟版本代表的 create 或 delete 操作才对该事物可见。
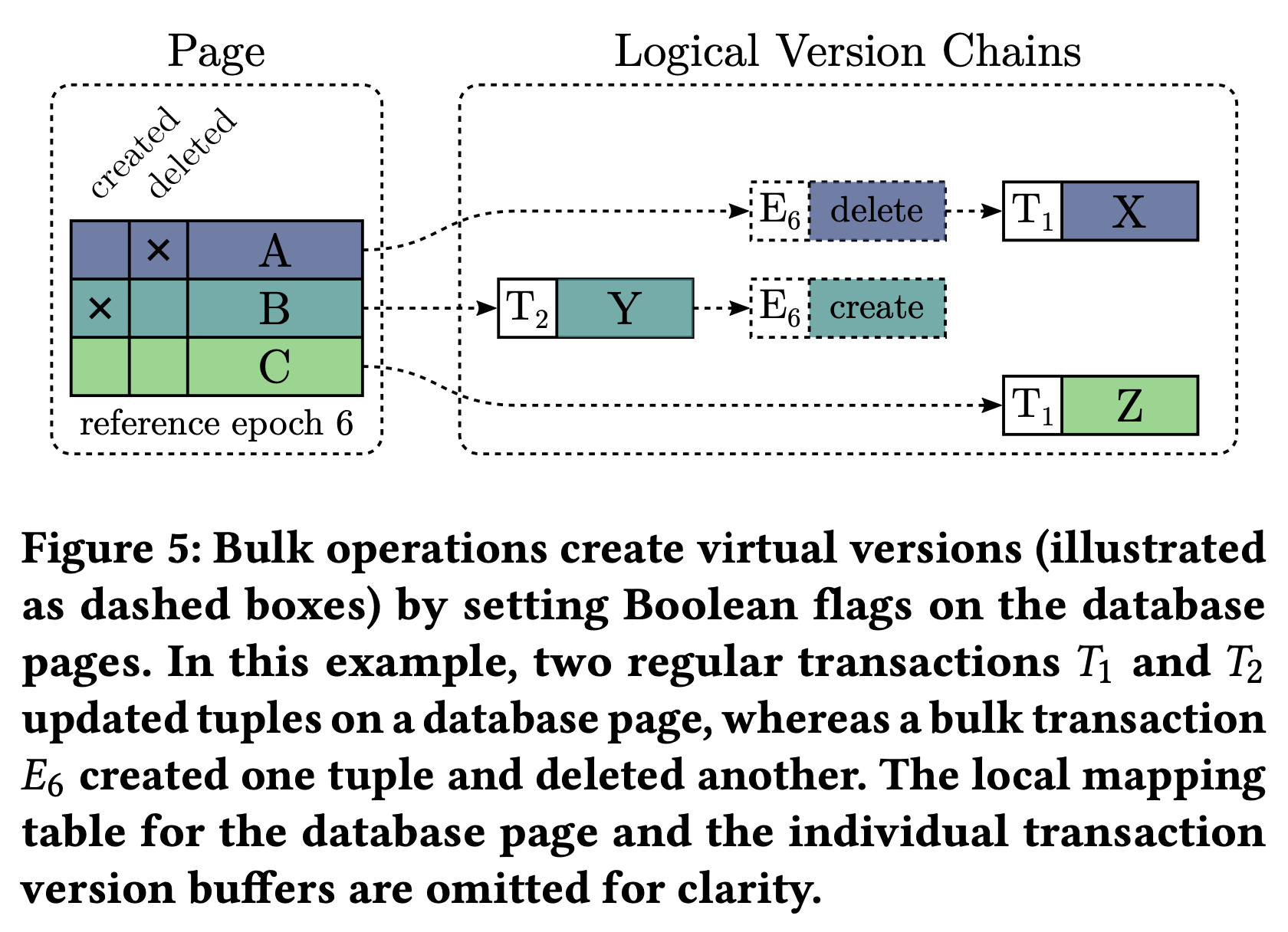
虚拟版本如何跟之前的 local mapping table 以及 version chain 结合起来对外提供服务呢?
- 每个 page header 都存了一个 reference bulk load epoch(后面简称 reference epoch),表示当前 page 的某些数据被一个 start epoch 为该值的 bulk operation 修改过,遍历 version chain 时如果遇到虚拟版本,那这个虚拟版本号就是这个 reference epoch。
- 每个 page 中的数据都维护了 2 个 flag 用来表示是否有 created 或 deleted 虚拟版本,这两个 flag 和 Tuple ID 编码在一起,占据 Tuple ID 的 2 个比特位,没有额外存储开销。bulk operation 修改数据时,首先把该 page 的 reference epoch 修改为它的 start epoch,然后修改该数据的 created 或 deleted 标志位,在 version chain 中新增虚拟版本。
- version chain 上的虚拟版本和常规事务的物理版本一起决定了数据的可见性。当且仅当事务的 start epoch 大于等于该 page 的 reference epoch 时该虚拟版本才可见;而物理版本则遵循之前提到一样可见性约束即可。
以上图为例,包含 bulk operation 在内前后有 3 个事务修改了这个 page:
- 最开始,一个以 T1 为 commit TS 的常规事务将第 1 个 tuple 从 X 修改成了 A,第 3 个 tuple 从 Z 修改成了 C。
- 接着一个 start epoch 为 E6 的 bulk operation 删除了第 1 个 tuple,创建了第 2 个值为 Y 的 tuple。这些信息通过 reference epoch 和对应的标志位记录在了 page 中。之后的事务在遍历 version chain 时如果遇到了虚拟版本就从 page 对应的 reference epoch 来比对 epoch 判断是否可见,通过标志位来判断该数据是 created 还是 deleted。
- 最后一个以 T2 为 commit TS 的常规事务将第 2 个 tuple 的值从 Y 修改成了 B。
在这个状态下,一个 start TS 为 t1,start epoch 为 E5 的事务只会读到 A 和 C,而如果它的 start epoch 为 E6 则能读到 Y 和 C。
理论上 epoch 和 transaction TS 可以使用同一个 timestamp 生成器,但有些问题需要解决。比如常规事务在提交时需要修改 version chain,把 transaction ID 改成 commit TS 后才能让数据对外可见。如果 bulk operation 也使用这个时间戳分配器,为了维护可见性约束,那么它也需要以相同的方式获取 transaction ID、start、commit TS 等时间戳,并且以相同的方式修改数据的 transaction ID 为 commit TS,这对修改大量数据的 bulk operation 说是无法忍受的。
同步 #
如何做到 bulk operation 执行过程中没有其他写事物执行呢?Umbra 使用了一个全局 mutex:
- 常规的 read-only 事务:不需要获取这个 mutex
- 常规的写事务:以 share 的方式获取这个 mutex
- bulk operation:以 exclusive 的方式获取这个 mutex
作者认为这个全局 mutex 带来的锁竞争是可以忽略的,除非正在执行一个 bulk operation。另外可以在 relation 或者 partition 上进行更细粒度的锁同步来降低这个开销,提高 bulk operation 的并发度。
在 page 中使用 reference epoch 统一表示所有数据的虚拟版本有一个缺陷:reference epoch 用来表示 page 上所有数据的虚拟版本,不能在单个 page 上同时存储不同的 reference epoch。因此在 bulk operation commit 时不会立即释放这个全局排它锁,而是将其降级为共享锁,允许执行常规的读写事务。等 bulk operation 的数据对所有活跃事务可见之后才释放这个共享锁,允许执行新的 bulk operation。
作者没有在这里直接讲怎样才算是可见,结合后面的垃圾回收机制来看,只要所有活跃事务的 start epoch 都大于等于这个 bulk operation 的 start epoch 后就对所有活跃事务可见了。也不用担心新的 bulk operation 修改了 page 的 reference epoch 导致原本应该可见的虚拟版本不可见了,因为在后续的 page 访问中,如果发现 page 的 reference epoch 小于所有活跃事务的 start epoch,会先进行一次 GC。这样就能保证每次 page 上进行 bulk operation 前不会有遗留有上次 bulk operation 产生的虚拟版本,而每次 page 上的 bulk operation 结束后都只会留下这次 bulk operation 产生的虚拟版本,不影响数据的可见性。
识别 Bulk Operations #
有两种方式来识别 bulk operatio。一个是用户显式指定,比如执行类似 SET TRANSACTION BULK WRITE 这样的语句。一个是自动推导和检测,Umbra 在查询优化时如果发现可能写入大量数据,就将当前事务设置为 bulk operation,另外如果在查询执行时检测到 version buffer 消耗了大量内存,也会将其设置 bulk operation。
垃圾回收 #
因为 bulk operation 不会生成任何物理版本,可以采用更懒惰的垃圾回收方法。每次访问包含虚拟版本的页面时都会检查 reference epoch 是否全局可见(小于等于所有活跃事务的 epoch)。当全局可见时,清除页面上所有数据的虚拟版本标志,重置 reference epoch。这些操作在每次获取到锁,访问页面,清理 local mapping table 的同时进行。
Further Considerations #
NUMA 架构 #
这里主要讨论了 NUMA 架构下的一些优化思路。面向 NUMA 架构需要尽可能避免 cross-socket 内存访问,尽可能使用本地内存完成事务。当事务执行时尽可能将其调度到 page 和其 version chain 所属的 NUMA region 上执行,需要的话也可以采用之前 HyPer 中使用 Morsel-Driven 计算调度方法。
Serializability #
这篇论文提供的 MVCC 能够满足 SI 隔离级别。在此基础上通过《 Fast Serializable Multi-Version Concurrency Control for Main-Memory Database Systems》(同样来自 TUM,2015 年发表在 SIGMOD)中提出的方法可以进一步实现 Serializable 隔离级别。
实验结果 #
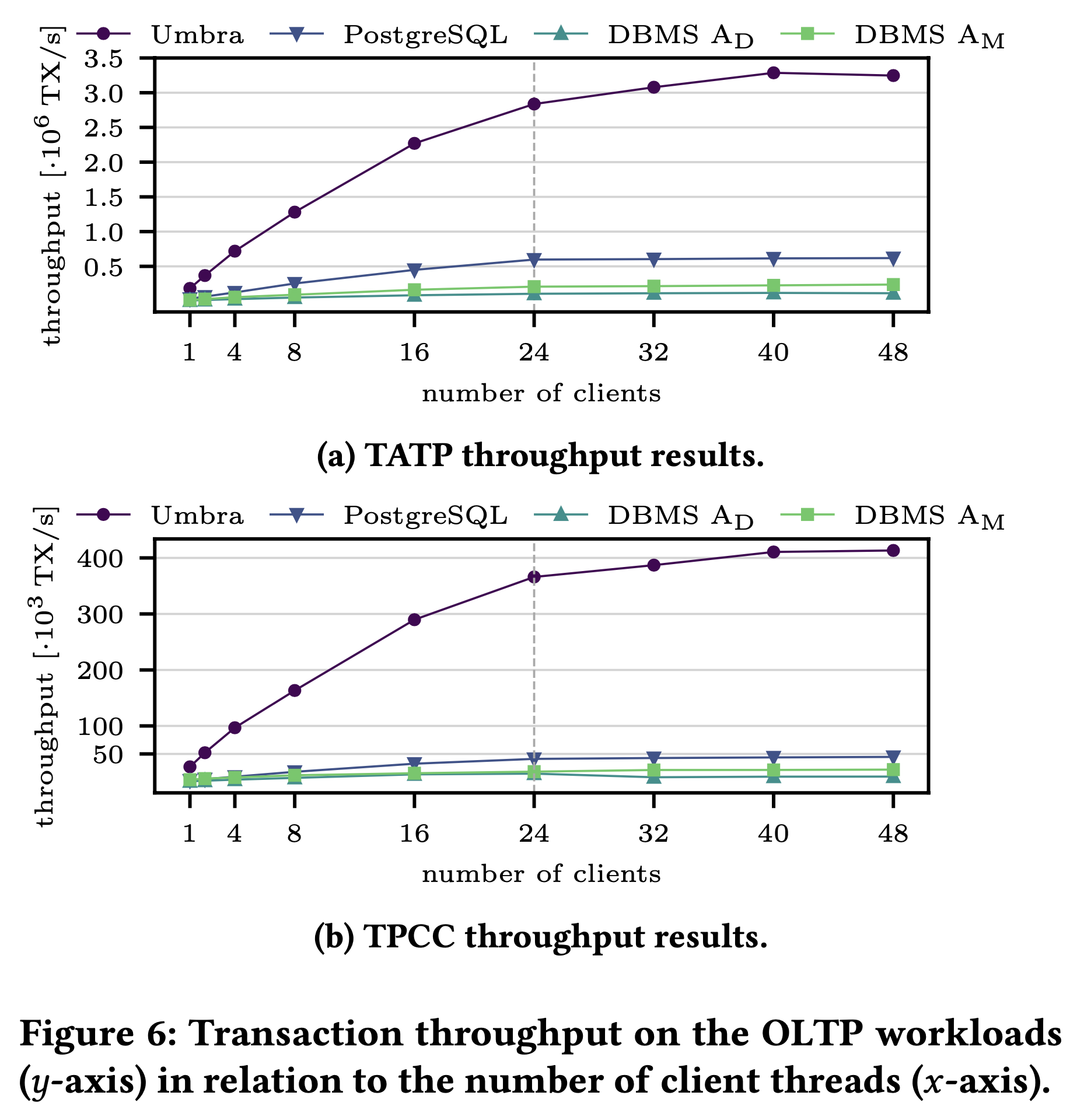
作者采用了 TATP 和 TPC-C 两个 OLTP 测试集分别测试重读和重写两个场景,测试中尽量调整 PG 和其他系统的配置使其发挥最佳性能,采用足够大的物理内存使大家尽量在内存中完成事务。从结果看,论文中提出的方法在性能上相比 PG 等有几乎 1 个数量级的优势:
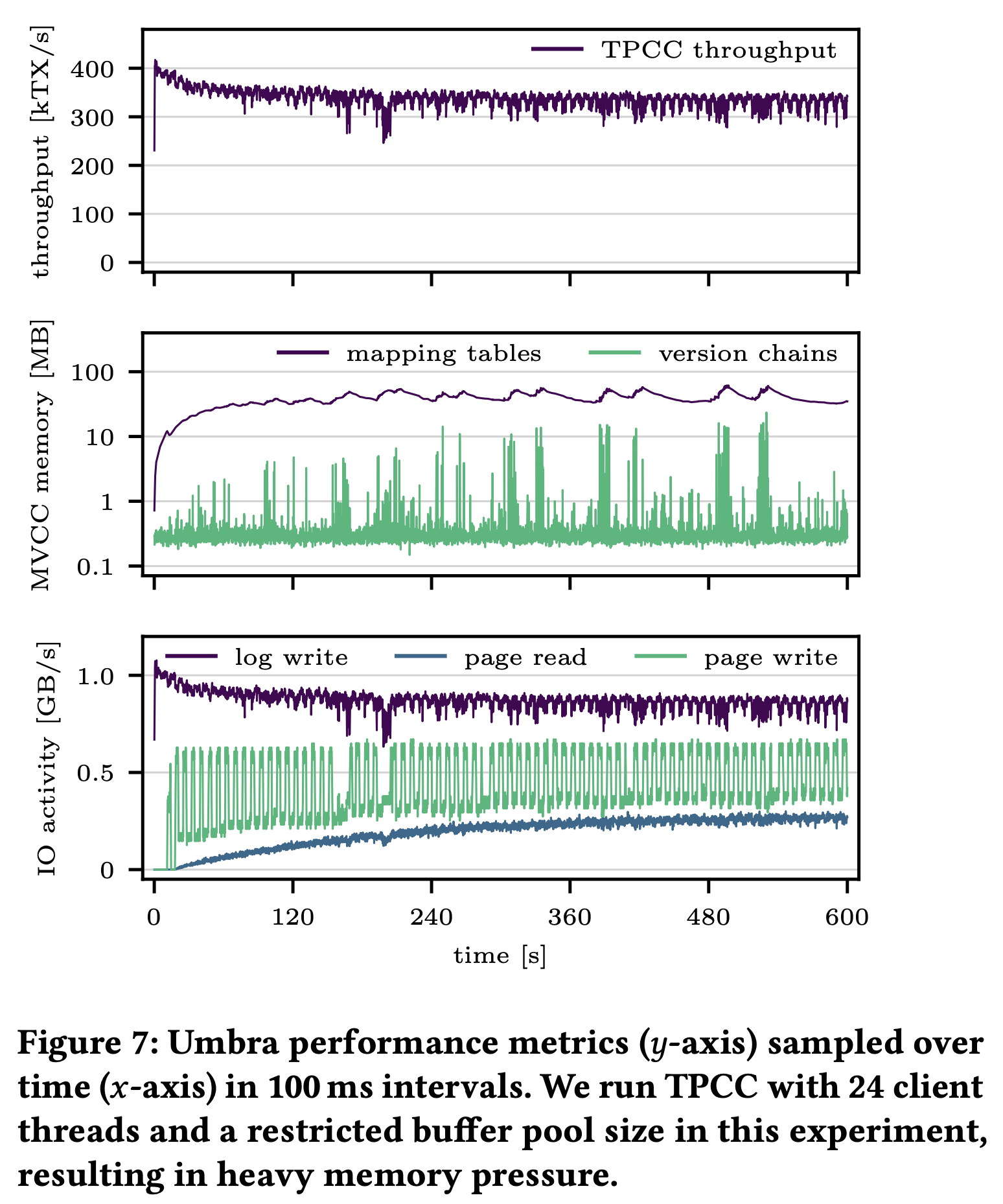
另外作者测试了 TPC-C 过程中内存里 version chain 和 local mapping table 的内存占用,看起来 version chain 的内存占用有抖动,但即使是波峰也很小只有 10MB 左右,看来 GC 还是比较及时:
作者还做了其他详细的测试,感兴趣的朋友可以详细读下论文原文。