[VLDB 2023] Scalable and Robust Snapshot Isolation for High-Performance Storage Engines
Table of Contents

夏特古道,2023
简介 #
这篇论文提出了一种能够避免 long-running OLAP query 影响 OLTP 事务、在多核 CPU 上 scale、支持 out-of-memory workload 的 MVCC 实现机制。
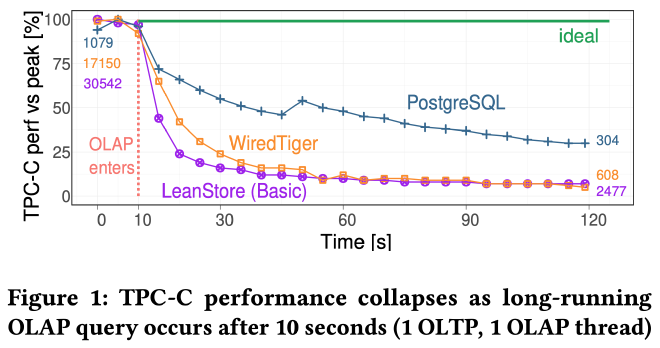
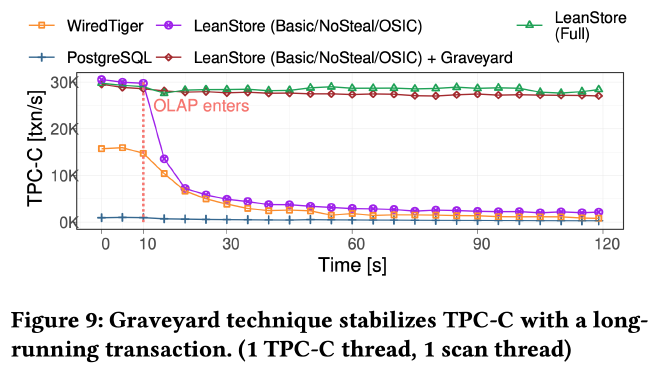
长时间运行的 OLAP 查询会严重影响 OLTP 事务延迟。例如上图,在 TPC-C 开始 10 秒后执行一个 sleep 语句,之后 WiredTiger 和 PostgreSQL 的 TPC-C 的性能都出现了大幅下跌,下跌幅度取决于 GC 激进和精确程度。
作者分析了 OLTP 性能下降的原因。长时间运行的 OLAP 查询会阻止 tombstone GC,从而导致 OLTP 事务执行 index range scan 时需要额外检查每个 index key 的 version chain,进行额外的 tombstone skipping, 影响事务性能。OLTP 事务执行过程中的 delete 和 update 会使这种情况变得更加糟糕。作者以 TPC-C 的 neworder 表为例,该表模拟了一个订单队列,各个事务会不断插入和删除订单,如果不能及时 GC tombstone,tombstone 也会越积越多。此外,对 index key 的更新也会遇到类似的问题,因为更新 index key 会先删除原来的 key 再插入新的 key。
而另一方面,当 OLTP 事务频繁更新某些数据时,长时间运行的 OLAP 查询延迟也会受到影响。因为采用了 N2O 的 version 顺序,新版本在 version chain 的头部,OLAP 查询需要跳过 version chain 前面的新版本才能获取到它需要的老版本数据。
有一个性质可以用来解决这个问题,那就是在任何时刻,每个 tuple 最多需要保留的版本数不会超过当前正在进行的事务总数。但没有任何 out-of-memory 系统实现了这种激进和精确的 GC 策略。
作者还详细分析了内存数据库和传统关系型数据库各自 MVCC 系统的实现原理,感兴趣的朋友可以参考论文的 “2.4 SI Commit Protocols” 小节。下面我们重点来看作者在论文中提出的 MVCC 系统实现。
系统设计概览 #
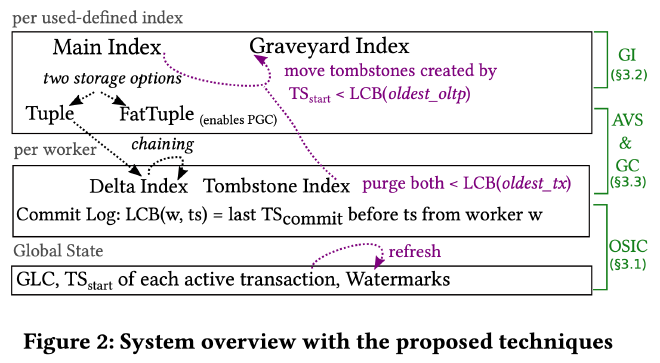
上图是作者提出的 MVCC 系统设计概览,总的来说可以分为如下几个方面:
- Commit Protocol:基于 Commit Log 实现了 LCB(Last Committed Before)接口,基于 LCB 接口实现了可见性检查,进而实现了 OSIC(Ordered Snapshot Instant Commit)。
- Garbage Collection:基于 oldest_oltp 和 oldest_tx 这两个 watermark 避免了长时间运行的 OLAP 查询导致的版本堆积使得 OLTP 事务延迟增大的问题。通过 Tombstone Index 记录所有被 OLTP 事务删除的数据,通过 Graveyard Index 存储所有不被任何 OLTP 事务使用的 tombstone,避免了标记删除的 tombstone 增加 OLTP 事务延迟,和双 watermark 机制共同解决了频繁插入删除导致 tombstone 堆积,事务延迟增加的问题。
- Version Storage:基于 off-row 的 Delta Index 和 in-row 的 FatTuple 这两种 version chain 存储格式之间的自适应转换实现了高效的数据读写和精确 GC。
Commit Protocol #
一些系统假设:采用全局逻辑时钟,每个事务开始和提交时分别获取 start 和 commit ts。采用 first writer wins 的原则解决写写冲突。每个工作线程内的事务串行执行,多个工作线程之间的事务并发执行。
OSIC 是 Ordered Snapshot Instant Commit 的简称,它实现了 SI 的事务隔离级别,通过 start ts 确定可见性,决定 snapshot,确定事务顺序等。和其他 out-of-memory 系统一样,事务 commit 时也不用再次修改 write set(比如将 write set 中的 start ts 修改为 commit ts)。
LCB 和 Snapshot Cache #
LCB 是 Last Committed Before 的简称,LCB(w, ts) 表示工作线程 w 在 ts 这个时间戳之前最后一条已提交事务的 commit ts。要想根据 start ts 确定事务的 snapshot,只需要知道所有工作线程 w 上的 LCB(w, start ts) 即可。
为了减少获取 LCB 的线程间同步开销,LCB 需要做到按需获取,且仅获取一次,理论上事务执行过程中最多获取 #W 次 LCB(#W 表示所有 worker 的数量):
- 仅在遇到其他 worker 写的数据版本(数据的版本信息中包含 worker id)时才去向对应的 worker 获取 LCB,避免获取无用的 LCB。
- 把获取到 LCB(wi, start ts) 缓存在 thread-local 的 snapshot cache 中,后面再遇到 worker wi 写的其他数据版本时就不再重复向该 worker 获取 LCB,而是直接读取 snapshot cache。

上图是根据 start ts、snapshot cache、LCB 进行可见性检查的伪代码,其中:
- tuple_ts_start 表示该 tuple 的版本号,tuple_w_i 表示写入该版本的 worker id。
- isVisible() 里第 1 个 if 语句先检查这个数据版本是否是当前 worker 写入的,是的话那肯定可见
- 第 2 个 if 语句根据具体的事务隔离级别调整可见性检查使用的事务 start ts,如果是 RC 隔离级别,就更新当前事务的 start ts 为最新 ts,尽量读到所有 worker 上最新的 commit
- 第 3 个 if 语句接着查本地的 snapshot cache,也就是伪代码中的 sc。sc 存储了每个 worker 上最近一次 LCB(wi, start ts) 对应的 commit ts。如果该 tuple 的版本号比上次 LCB 查到的 commit ts 还小,该 tuple 一定对当前事务可见。
- 第 4 个 if 语句检查 snapshot cache 是否需要更新。缓存的内容实际是 tuple_w_i 这个 worker 在 tx_ts_start 这个时间戳对应的 last_commit_ts。如果缓存的 cache_ts_start 比 tx_ts_start 更小(不会发生更大的情况),这时候就需要更新 LCB 缓存
- 如果前面的检查都 fail 了,到这里我们已经拿到了准确的 LCB(tuple_w_i, tx_ts_start) 的结果并将其缓存在了 sc[tuple_w_i] 中,最后只需要根据准确的 last_commit_ts 做一次比较即可判断该版本是否可见。
Commit Log #
为了计算每个工作线程 w 上的 LCB(w, ts),需要为每个工作线程维护一个 Commit Log 队列,用来存储 start ts 和对应 commit ts 的映射关系,处理 LCB 请求时只需要查找 Commit Log 返回对应的 commit ts 即可。
Commit Log 会被并发读写,因此也需要合适的线程间同步机制。每个 Commit Log 都有一把锁,事务 commit 时需要获得写锁,将 commit ts 和对应的 Commit Log 写入后才完成事务提交,释放锁,之后其他拥有更大 start ts 的事务就能看见提交后的最新版本了。
对每个 worker 上的 Commit Log 队列来说,因为只需要为每个活跃事务保留一个 Commit Log,因此总共只需要保留 #W (worker 总数)条 Commit Log。每个 worker 开启新事务时都会检查 Commit Log 队列是否已满,如果队列已满,该 worker 需要收集所有活跃事务的 start ts,剔除那些活跃事务不可见的 Commit Log,限制 Commit Log 的总大小。
Garbage Collection #

为了解决因长时间运行的 OLAP 查询导致 MVCC 版本堆积而拖慢 OLTP 事务的问题,作者通过优化器将查询分为 OLAP 和 OLTP,并维护了 oldest_tx 和 oldest_oltp 这两个 watermark。它们分别表示最老的 OLAP 事务和最老的 OLTP 事务的 start ts。这样就可以对 newest_olap 到 oldest_oltp 之间的版本进行 Cooperative GC(每个 worker 回收自己创建的位于 LCB(w, oldest_tx or oldest_oltp) 之间的 MVCC 版本),从而避免长时间运行的 OLAP 事务对 OLTP 事务的影响。
使用 start ts 的最高有效位来区分 OLTP 和 OLAP。事务结束后,start ts 将以 1/#W(#W 表示 worker 总数)的概率更新到全局共享数组中,从而可以通过分析该数组中的 OLTP 和 OLAP start ts 来获取这两个 watermark。
Tombstone #
删除数据会产生 tombstone,而因为 long-running OLAP query 的存在,这些 tombstone 会在 main index 中一直累积,增加 OLTP 事务延迟:因为索引中没有数据的 MVCC 信息,要想知道一个数据是否删除了,需要先读索引再去 main index 拿到具体的 tuple,最后根据 tuple 上的 MVCC 信息判断数据是否已删除。
Graveyard Index #
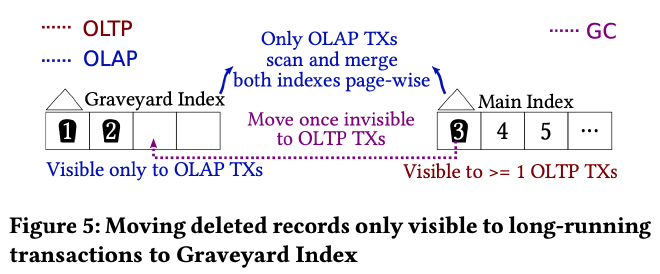
因为被 tombstone 标记删除的数据只对那些 long-running OLAP query 可见,对那些 start ts 更大的 OLTP 事务不可见。因此作者引入了一个额外的 graveyard index 数据结构来存储这样的 tombstone,只要 tombstone 的 start ts 小于 oldest_oltp 就将其从 main index 移到 Graveyard Index。
OLAP query 需要同时查询 main index 和 Graveyard Index 来获取所有可见的数据版本,而 OLTP query 只需要查询 main index 即可,牺牲少量 OLAP 查询性能保障了 OLTP 事务延迟不受 long-running OLAP query 的影响。
Tombstone Index #
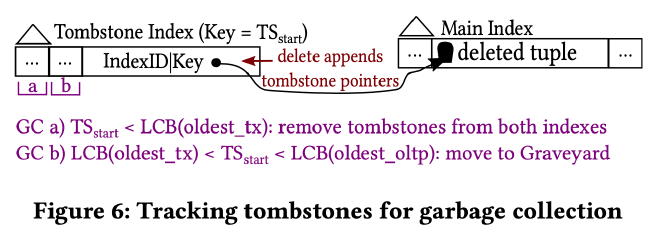
为了知道有哪些 tombstone 并及时对它们进行 GC,作者以去中心化的方式在每个 worker 上维护了一个 Tombstone Index。Tombstone Index 是一个 append-optimized B+ tree,key 由 start ts、command id 组成,value 为该 tombstone 的 tuple key。根据 oldest_tx 以及 oldest_oltp 这两个 watermark 确定 Tombstone Index 中的 tombstone 是应该直接删掉还是从 main index 转移到 graveyard index。
Version Storage #
同时采用了 Delta Index 和 FatTuple 两种版本存储方式,默认采用 Delta Index。
Delta Index #
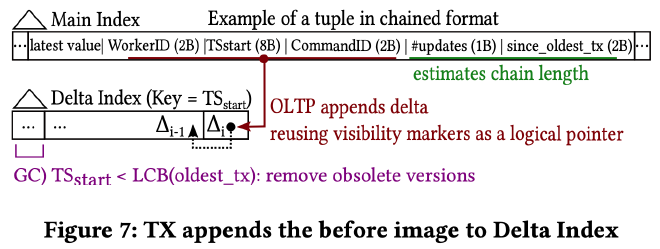
如上图所示,默认情况下所有老版本数据都存储在每个 worker 线程的 Delta Index 中,main index 只存储最新版本的 tuple 和其 version chain 的一些 metadata,这些 metadata 包括:
- WorkerID 和 TSstart:共同决定了该 tuple 最新版本的可见性
- WorkerID、TSstart 和 CommandID 共同构成了 Delta Index 的 key,同时也指向了 version chain 中上一个更老版本的数据。CommandID 主要用来区分同一个事物的不同操作,在 Delta Index 中可以省略,使用(WorkerID、TSstart、IndexID、Key)作为 Delta Index 的 key。
- #updates 和 since_oldest_tx:用来估算 version chain 的长度。因为精确的维护 version chain 的长度代价太大,作者采用了启发式的估算方式。#updates 表示在 oldest_tx 这个 watermark 不变的情况下该 tuple 最多更新了多少次,反应了受 long-running OLAP query 影响的情况下累积的版本数。since_oldest_tx 存储的是 oldest_tx 的低 16 位(2 字节)。每当事务更行时都会检查当前 oldest_tx 的低 16 位是否和 since_oldest_tx 相等,是的话就把 #update 加 1,否的话就重置 #update 计数器。当 #update 超过 worker 总数时就将其转成 FatTuple 的存储方式。
FatTuple #
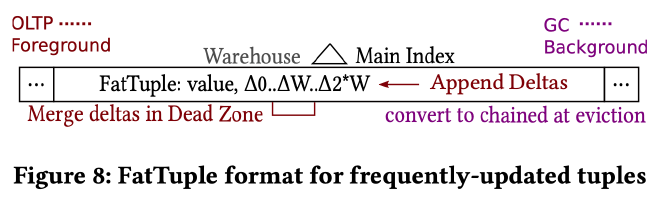
当 tuple 被频繁更新时会被自动转换为 FatTuple,把所有的数据版本 delta 都 inline 的存储在 main index 的 FatTuple 中。因为每个 FatTuple 只需要存储 #W 个数据版本,作者在 FatTuple 的基础上实现了 on-demand precise garbage collection(OPGC),OPGC 模式下会首先将 newest_olap 到 oldest_oltp 这个 dead zone 内的 delta GC 掉,如果还没有足够的槽位再去收集所有正在运行事务的 start ts,确定所有的 dead zone 后 GC 所有不需要的 delta。关于 precise garbage collection 可以参考《Long-lived Transactions Made Less Harmful》。
另外,因为 GC 时只会扫描 Tombstone Index 和 Delta Index,为了保证 FatTuple 中的旧版本也能被 GC,在 page eviction 时需要将 FatTuple 转成 Delta Index。
Durability and Recovery #
因为所有事务操作都有 WAL,所以前面提到的数据结构比如 Commit Log、Graveyard Index、Tombstone Index、Delta Index 都没有 durability 要求。
恢复也比较简单,在 analysis 阶段确定 winning transactions,在 redo 阶段 delete 操作直接将 main index 上的 tombstone 删掉。每个 worker 的 Commit Log 初始化为最后一个 winning transaction 的 commit ts。
事务 abort 比较特殊。worker 的 Commit Log 中只存储了成功提交的事务,事务 abort 时需要将它所有的改动回滚(可能分散在 Delta Index、Tombstone Index 中),将它的 start ts 也回收,用于该 worker 的下一个事务的 start ts。
Evaluation #
从作者后面的实验来看,Graveyard Index 能够显著降低 long-running OLAP query 对 TPC-C 性能的影响:
而 FatTuple 的设计也使得 OLAP scan 的性能不受影响: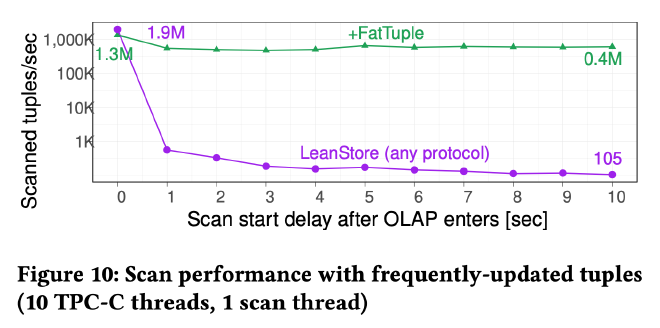
后面作者还做了关于 “TPC-C + Scan: Scalability”、“Out-of-Memory Breakdown”、“Bulk Loading”、“Out-of-Memory Key/Value”、“Deterministic Execution Under Contention” 等实验,感兴趣的朋友可以详细阅读 “4 EVALUATION” 这一节,从实验结果来看整体效果不错。